![]()

Introducción¶
Este taller te enseñará a usar Python junto con librerías como pandas y openpyxl para trabajar con archivos Excel. Aprenderás a leer, escribir, pivotear tablas, agrupar y contar elementos, además de extraer datos de páginas web. Es ideal para usuarios intermedios o avanzados de Excel que buscan potenciar su trabajo con Python.
Tipos de Datos: CSV y Excel¶
CSV: CSV es un formato simple para almacenar datos tabulares, con valores separados por comas u otros delimitadores. Es ampliamente usado para intercambiar datos entre aplicaciones.
Excel: Excel es una herramienta de hojas de cálculo de Microsoft. Los archivos pueden contener múltiples hojas, gráficos, fórmulas y datos formateados, con XLSX como el formato moderno y XLS como el más antiguo.
| Característica | Archivo CSV | Archivo Excel |
|---|---|---|
| Estructura del Archivo | Datos como texto plano, con registros separados por comas u otro delimitador. | Organizados en hojas de cálculo con múltiples filas, columnas, fórmulas, gráficos y otros elementos. |
| Capacidades de Formateo | No admite formateo, solo contiene datos. | Admite formatos de celda, fórmulas, estilos, gráficos y más, además de los datos. |
| Compatibilidad | Altamente compatible con muchas aplicaciones y lenguajes de programación. | Compatible principalmente con Microsoft Office, aunque puede ser manejado por otras aplicaciones. |
Utilización con Pandas¶
Para trabajar con datos CSV y Excel en Python, la librería pandas proporciona funcionalidades específicas:
CSV: Para leer un archivo CSV en pandas, se utiliza la función
pd.read_csv(), que carga los datos en un DataFrame de pandas. Para escribir datos en un archivo CSV, se puede utilizarDataFrame.to_csv().import pandas as pd # Leer un archivo CSV df = pd.read_csv('archivo.csv') # Escribir datos en un archivo CSV df.to_csv('nuevo_archivo.csv', index=False)
Excel: Para leer un archivo Excel en pandas, se puede utilizar
pd.read_excel(), que carga los datos en un DataFrame. Para escribir datos en un archivo de Excel, se puede utilizarDataFrame.to_excel().import pandas as pd # Leer un archivo de Excel df = pd.read_excel('archivo.xlsx', sheet_name='Sheet1') # Escribir datos en un archivo de Excel df.to_excel('nuevo_archivo.xlsx', index=False)
Utilizando Pandas con Excel¶
Conjunto de Datos¶
En este tutorial, utilizaremos un archivo de Excel con múltiples hojas que hemos creado a partir de los datos de puntuaciones IMDB disponibles en Kaggle. Puedes acceder y descargar el archivo desde este enlace.
Nuestro archivo de Excel consta de tres hojas: 1900, 2000 y 2010, cada una conteniendo datos de películas correspondientes a esos años.
Utilizaremos este conjunto de datos para explorar la distribución de calificaciones de las películas, identificar aquellas con las calificaciones y ganancias netas más altas, y calcular estadísticas relevantes sobre el conjunto de películas.
Descripción de los datos
La siguiente tabla proporciona una descripción detallada de los diferentes tipos de datos presentes en el conjunto de datos:
| Columna | Descripción | Tipo de Datos |
|---|---|---|
| Title | Título de la película | object |
| Year | Año de lanzamiento | float64 |
| Genres | Géneros de la película | object |
| Language | Idioma de la película | object |
| Country | País de origen de la película | object |
| Content Rating | Clasificación de contenido | object |
| Duration | Duración de la película (min) | float64 |
| Aspect Ratio | Relación de aspecto | float64 |
| Budget | Presupuesto de la película | float64 |
| Gross Earnings | Ganancias brutas | float64 |
| Director | Director de la película | object |
| Actor 1 | Primer actor principal | object |
| Actor 2 | Segundo actor principal | object |
| Actor 3 | Tercer actor principal | object |
| Facebook Likes - Director | Likes en Facebook del director | float64 |
| Facebook Likes - Actor 1 | Likes en Facebook del Actor 1 | float64 |
| Facebook Likes - Actor 2 | Likes en Facebook del Actor 2 | float64 |
| Facebook Likes - Actor 3 | Likes en Facebook del Actor 3 | float64 |
| Facebook Likes - cast Total | Total de Likes del reparto en Facebook | int64 |
| Facebook likes - Movie | Likes en Facebook de la película | int64 |
| Facenumber in posters | Número de caras en posters | float64 |
| User Votes | Votos de usuarios | int64 |
| Reviews by Users | Reseñas de usuarios | float64 |
| Reviews by Crtiics | Reseñas de críticos | float64 |
| IMDB Score | Puntuación IMDB | float64 |
Leer y guardar datos¶
Aprenderemos cómo leer datos de un archivo Excel y fusionar múltiples hojas en un solo DataFrame utilizando pandas en Python.
Paso 01: Intalar e Importar librerías
Necesitamos instalar la librerías necesarías para este ejercicio:
terminal
pip install pandas openpyxl xlrdNota: si utilizan Google Colab, estas librerías deberían estar instaladas.
Luego, importamos las librerías de pandas:
import pandas as pd
Paso 02: Leer las hojas del excel
Necesitamos especificar la ruta del archivo, para luego leer las hojas
# Especificar la ruta del archivo Excel
excel_file = 'https://raw.githubusercontent.com/fralfaro/MADS-Workshops/main/docs/TallerPandas/data/movies.xls'
# Lee los nombres de las hojas
nombres_hojas = pd.ExcelFile(excel_file).sheet_names
# Imprimir la lista con el nombre de las hojas en excel
nombres_hojas
Paso 03: Leer los archivos individualmente
# Leer archivos
df_1900 = pd.read_excel(excel_file, sheet_name=nombres_hojas[0])
df_2000 = pd.read_excel(excel_file, sheet_name=nombres_hojas[1])
df_2010 = pd.read_excel(excel_file, sheet_name=nombres_hojas[2])
Paso 04: Juntar los archivos en un solo Dataframe
# Juntar los DataFrames en uno solo
df = pd.concat([df_1900, df_2000, df_2010], ignore_index=True)
# Mostrar las primeras filas del DataFrame
df.head()
Paso 05: Guardar resultados en Excel
# Especifica la ruta donde deseas guardar el archivo Excel
ruta_archivo_excel = 'movies2.xlsx'
# Crea un objeto ExcelWriter
with pd.ExcelWriter(ruta_archivo_excel) as writer:
# Guarda el DataFrame en una hoja llamada '1900'
df_1900.to_excel(writer, sheet_name='1900', index=False)
# Guarda otro DataFrame en otra hoja llamada '2000'
df_2000.to_excel(writer, sheet_name='2000', index=False)
# Guarda otro DataFrame en otra hoja llamada '2010'
df_2010.to_excel(writer, sheet_name='2010', index=False)
Operaciones Básicas con Pandas¶
# Mostrar las primeras filas del DataFrame
print("Primeras filas del DataFrame:")
df.head(5)
# Mostrar las ultimas filas del DataFrame
print("Ultimas filas del DataFrame:")
df.tail(5)
# Obtener las dimensiones del DataFrame
print("Dimensiones del DataFrame:")
print(df.shape)
# Mostrar todas las columnas del DataFrame
print("Columnas del DataFrame:")
df.columns
# Valores nulos por columna
df.isnull().sum()
# Valores unicos por columnas
print("Valores unicos por columnas:")
df.nunique()
# Mostrar información del DataFrame
print("Información del DataFrame:")
df.info()
# Calcular estadísticas descriptivas del DataFrame
print("Estadísticas descriptivas del DataFrame:")
df.describe()
# Seleccionar una columna específica del DataFrame
print("Valores únicos de una columna específica:")
df['Year'].unique()
# Obtener total de valores únicos de la columna específica
print("Total de valores únicos de una columna específica:")
df['Year'].nunique()
# Filtrar filas que cumplan una condición
print("Filtrar filas que cumplan una condición:")
filtered_df = df[df['Year'] > 2000]
filtered_df.head()
# Contar valores de una columan específica
print("Conteo de los distintos lenguaje de las peliculas:")
df['Language'].value_counts()
# Ordenar el DataFrame por una columna específica
print("Ordenar el DataFrame por una columna específica:")
sorted_df = df.sort_values(by='Title', ascending=False)
sorted_df.head()
Comando apply
# Aplicar una función lambda a cada entrada de la columna 'Genres' para contar el número de géneros en cada entrada
total_generos = df['Genres'].apply(lambda x: len(x.split('|')))
# Imprimir el máximo valor entre todos los conteos de géneros
print("Máximo número de géneros en una entrada:", max(total_generos))
Trabajar con duplicados
# Contar el número de filas duplicadas en el DataFrame
num_filas_duplicadas = df.duplicated().sum()
print("Número de filas duplicadas en el DataFrame:", num_filas_duplicadas)
# Eliminar filas duplicadas del DataFrame
df = df.drop_duplicates()
num_filas_duplicadas = df.duplicated().sum()
print("Número de filas duplicadas en el DataFrame:", num_filas_duplicadas)
Crear nuevas columnas
import math
# Redondear cada valor de la columna 'Duration' al múltiplo de 30 más cercano
df['DurationRounded'] = df['Duration'].fillna(0).apply(lambda x: math.ceil(x / 30) * 30)
# Imprimir valores
df['DurationRounded'].unique()
# Función para obtener la década correspondiente
def obtener_decada(year):
if year < 1900:
return None
elif year < 2000:
return '1900'
elif year < 2010:
return '2000'
else:
return '2010'
# Aplicar la función a la columna 'Year' para crear la nueva columna 'Decade'
df['Decade'] = df['Year'].fillna(0).apply(obtener_decada)
# Imprimir valores
df['Decade'].unique()
# Definición de los intervalos
bins = [0, 5, 7, 10]
# Definición de las etiquetas
labels = ['Bajo', 'Medio', 'Alto']
# Aplicación de la función pd.cut() para crear la nueva columna
df['IMDB Score Category'] = pd.cut(df['IMDB Score'], bins=bins, labels=labels)
# Imprimir valores
df['IMDB Score Category'].unique()
# Definir el diccionario de países y continentes
continentes_por_pais = {
'USA': 'North America',
'Germany': 'Europe',
'Japan': 'Asia',
'Denmark': 'Europe',
'UK': 'Europe',
'Italy': 'Europe',
'France': 'Europe',
'West Germany': 'Europe',
'Sweden': 'Europe',
'Soviet Union': 'Europe',
'Iran': 'Asia',
'Australia': 'Oceania',
'Libya': 'Africa',
'Canada': 'North America',
'South Korea': 'Asia',
'Brazil': 'South America',
'Netherlands': 'Europe',
'China': 'Asia',
'Norway': 'Europe',
'Switzerland': 'Europe',
'New Zealand': 'Oceania',
'Hong Kong': 'Asia',
'Peru': 'South America',
'India': 'Asia',
'Spain': 'Europe',
'Aruba': 'North America',
'Mexico': 'North America',
'Czech Republic': 'Europe',
'Taiwan': 'Asia',
'Argentina': 'South America',
'Thailand': 'Asia',
'New Line': 'North America',
'Afghanistan': 'Asia',
'Russia': 'Europe',
'Ireland': 'Europe',
'Colombia': 'South America',
'Romania': 'Europe',
'Philippines': 'Asia',
'Hungary': 'Europe',
'Cameroon': 'Africa',
'South Africa': 'Africa',
'Israel': 'Asia',
'Poland': 'Europe',
'Turkey': 'Asia',
'Slovakia': 'Europe',
'Greece': 'Europe',
'Iceland': 'Europe',
'Official site': None,
'Georgia': 'Europe',
'Finland': 'Europe',
'Belgium': 'Europe',
'Indonesia': 'Asia',
'Nigeria': 'Africa',
'Dominican Republic': 'North America',
'United Arab Emirates': 'Asia',
'Egypt': 'Africa',
'Bulgaria': 'Europe',
'Bahamas': 'North America',
'Cambodia': 'Asia',
'Kyrgyzstan': 'Asia',
'Kenya': 'Africa',
'Slovenia': 'Europe',
'Pakistan': 'Asia',
'Chile': 'South America',
'Panama': 'North America'
}
# Crear una nueva columna 'Continent' basada en el diccionario de países y continentes
df['Continent'] = df['Country'].map(continentes_por_pais)
# Imprimir valores
df['Continent'].unique()
Operaciones con GroupBy¶

# Agrupar por el año y calcular la media de IMDB Score
df_grouped_year = df.groupby('Year')['IMDB Score'].mean()
df_grouped_year
# Agrupar por año y país y calcular la suma de User Votes
df_grouped_year_country = df.groupby(['Year', 'Country'])['User Votes'].sum()
df_grouped_year_country
# Agrupar por año y calcular varias estadísticas para IMDB Score
df_grouped_year_stats = df.groupby('Year')['IMDB Score'].agg(['mean', 'median', 'std'])
df_grouped_year_stats
# Definir una función personalizada para calcular la diferencia entre el máximo y el mínimo de User Votes
def custom_function(x):
return x.max() - x.min()
# Agrupar por país y aplicar la función personalizada a User Votes
df_grouped_country_custom = df.groupby('Country')['User Votes'].agg(custom_function)
df_grouped_country_custom
# Dividir IMDB Score en intervalos y contar el número de películas en cada intervalo
bins = [0, 5, 7, 10]
labels = ['Bajo', 'Medio', 'Alto']
df['IMDB Score Category'] = pd.cut(df['IMDB Score'], bins=bins, labels=labels)
df_grouped_imdb_category_count = df.groupby('IMDB Score Category').size()
df_grouped_imdb_category_count
Pivot Tables¶
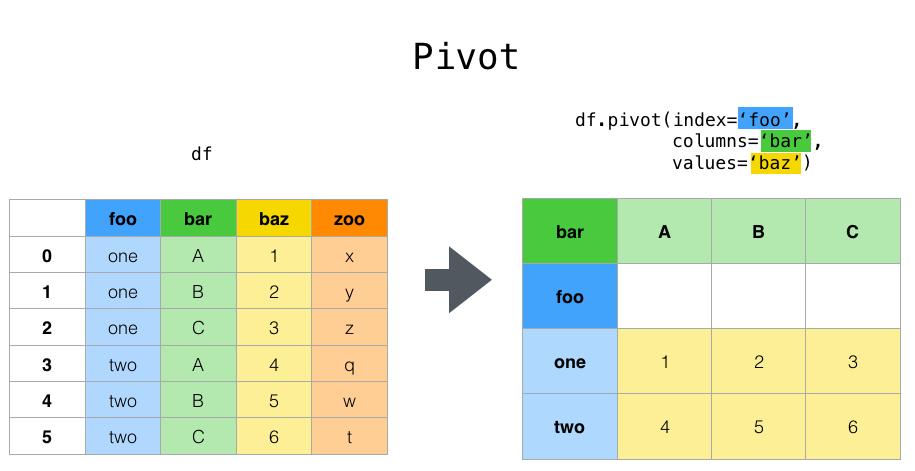
# Crear una pivot table para calcular la suma de User Votes según el año y el país
pivot_table_basic = df.pivot_table(values='User Votes', index='Decade', columns='Continent', aggfunc='mean')
pivot_table_basic
# Crear una pivot table para calcular la media de IMDB Score según el año y el Content Rating
pivot_table_mean = df.pivot_table(values='IMDB Score', index='DurationRounded', columns='Country', aggfunc='mean').fillna(0)
pivot_table_mean