![]()

Introduction¶
This workshop will teach you how to use Python along with libraries like pandas and openpyxl to work with Excel files. You will learn how to read, write, pivot tables, group and count items, as well as extract data from web pages. It is ideal for intermediate or advanced Excel users looking to boost their work with Python.
Data Types: CSV and Excel¶
CSV: CSV is a simple format for storing tabular data, with values separated by commas or other delimiters. It is widely used to exchange data between applications.
Excel: Excel is a spreadsheet tool from Microsoft. Files can contain multiple sheets, charts, formulas, and formatted data, with XLSX as the modern format and XLS as the older one.
| Feature | CSV File | Excel File |
|---|---|---|
| File Structure | Data as plain text, with records separated by commas or other delimiter. | Organized into spreadsheets with multiple rows, columns, formulas, charts, and other elements. |
| Formatting Capabilities | Does not support formatting, only holds data. | Supports cell formats, formulas, styles, charts, and more in addition to data. |
| Compatibility | Highly compatible with many applications and programming languages. | Primarily compatible with Microsoft Office, although can be handled by other applications. |
Using Pandas¶
To work with CSV and Excel data in Python, the pandas library provides specific functionality:
- CSV: To read a CSV file in pandas, you use the
pd.read_csv()function, which loads the data into a pandas DataFrame. To write data to a CSV file, you can useDataFrame.to_csv().
import pandas as pd
# Read a CSV file
df = pd.read_csv('file.csv')
# Write data to a CSV file
df.to_csv('new_file.csv', index=False)
- Excel: To read an Excel file in pandas, you can use
pd.read_excel(), which loads the data into a DataFrame. To write data to an Excel file, you can useDataFrame.to_excel().
import pandas as pd
# Read an Excel file
df = pd.read_excel('file.xlsx', sheet_name='Sheet1')
# Write data to an Excel file
df.to_excel('new_file.xlsx', index=False)
Using Pandas with Excel¶
Dataset¶
In this tutorial, we will use a multi-sheet Excel file that we created from the IMDB ratings data available on Kaggle. You can access and download the file from this link.
Our Excel file consists of three sheets: 1900, 2000, and 2010, each containing movie data for those years.
We will use this dataset to explore the rating distribution of movies, identify those with the highest ratings and net earnings, and calculate relevant statistics about the set of movies.
Data Description
The following table provides a detailed description of the different types of data present in the dataset:
| Column | Description | Data Type |
|---|---|---|
| Title | Movie title | object |
| Year | Year of release | float64 |
| Genres | Movie genres | object |
| Language | Movie language | object |
| Country | Country of origin of the movie | object |
| Content Rating | Content rating | object |
| Duration | Movie duration (min) | float64 |
| Aspect Ratio | float64 | |
| Budget | Movie budget | float64 |
| Gross Earnings | float64 | |
| Director | Movie director | object |
| Actor 1 | First lead actor | object |
| Actor 2 | Second lead actor | object |
| Actor 3 | Third lead actor | object |
| Facebook Likes - Director | Director's Facebook Likes | float64 |
| Facebook Likes - Actor 1 | Actor 1's Facebook Likes | float64 |
| Facebook Likes - Actor 2 | Actor 2's Facebook Likes | float64 |
| Facebook Likes - Actor 3 | Actor 3's Facebook Likes | float64 |
| Facebook Likes - cast Total | Total Facebook Likes of the cast | int64 |
| Facebook likes - Movie | Movie's Facebook Likes | int64 |
| Facenumber in posters | Number of faces in posters | float64 |
| User Votes | User Votes | int64 |
| Reviews by Users | User Reviews | float64 |
| Reviews by Crtiics | Critic Reviews | float64 |
| IMDB Score | IMDB Score | float64 |
Reading and Saving Data¶
We will learn how to read data from an Excel file and merge multiple sheets into a single DataFrame using pandas in Python.
Step 01: Install and Import Libraries
We need to install the libraries needed for this exercise:
terminal
pip install pandas openpyxl xlrdNote: If you are using Google Colab, these libraries should be installed.
Next, we import the pandas libraries:
import pandas as pd
Step 02: Read the Excel sheets
We need to specify the file path, in order to then read the sheets
# Especificar la ruta del archivo Excel
excel_file = 'https://raw.githubusercontent.com/fralfaro/MADS-Workshops/main/docs/TallerPandas/data/movies.xls'
# Lee los nombres de las hojas
nombres_hojas = pd.ExcelFile(excel_file).sheet_names
# Imprimir la lista con el nombre de las hojas en excel
nombres_hojas
['1900s', '2000s', '2010s']
Step 03: Read the files individually
# Leer archivos
df_1900 = pd.read_excel(excel_file, sheet_name=nombres_hojas[0])
df_2000 = pd.read_excel(excel_file, sheet_name=nombres_hojas[1])
df_2010 = pd.read_excel(excel_file, sheet_name=nombres_hojas[2])
Step 04: Combine the files into a single Dataframe
# Juntar los DataFrames en uno solo
df = pd.concat([df_1900, df_2000, df_2010], ignore_index=True)
# Mostrar las primeras filas del DataFrame
df.head()
| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | ... | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Intolerance: Love's Struggle Throughout the Ages | 1916.0 | Drama|History|War | NaN | USA | Not Rated | 123.0 | 1.33 | 385907.0 | NaN | ... | 436.0 | 22.0 | 9.0 | 481 | 691 | 1.0 | 10718 | 88.0 | 69.0 | 8.0 |
| 1 | Over the Hill to the Poorhouse | 1920.0 | Crime|Drama | NaN | USA | NaN | 110.0 | 1.33 | 100000.0 | 3000000.0 | ... | 2.0 | 2.0 | 0.0 | 4 | 0 | 1.0 | 5 | 1.0 | 1.0 | 4.8 |
| 2 | The Big Parade | 1925.0 | Drama|Romance|War | NaN | USA | Not Rated | 151.0 | 1.33 | 245000.0 | NaN | ... | 81.0 | 12.0 | 6.0 | 108 | 226 | 0.0 | 4849 | 45.0 | 48.0 | 8.3 |
| 3 | Metropolis | 1927.0 | Drama|Sci-Fi | German | Germany | Not Rated | 145.0 | 1.33 | 6000000.0 | 26435.0 | ... | 136.0 | 23.0 | 18.0 | 203 | 12000 | 1.0 | 111841 | 413.0 | 260.0 | 8.3 |
| 4 | Pandora's Box | 1929.0 | Crime|Drama|Romance | German | Germany | Not Rated | 110.0 | 1.33 | NaN | 9950.0 | ... | 426.0 | 20.0 | 3.0 | 455 | 926 | 1.0 | 7431 | 84.0 | 71.0 | 8.0 |
5 rows × 25 columns
Step 05: Save results in Excel
# Especifica la ruta donde deseas guardar el archivo Excel
ruta_archivo_excel = 'movies2.xlsx'
# Crea un objeto ExcelWriter
with pd.ExcelWriter(ruta_archivo_excel) as writer:
# Guarda el DataFrame en una hoja llamada '1900'
df_1900.to_excel(writer, sheet_name='1900', index=False)
# Guarda otro DataFrame en otra hoja llamada '2000'
df_2000.to_excel(writer, sheet_name='2000', index=False)
# Guarda otro DataFrame en otra hoja llamada '2010'
df_2010.to_excel(writer, sheet_name='2010', index=False)
Basic Operations with Pandas¶
# Mostrar las primeras filas del DataFrame
print("Primeras filas del DataFrame:")
df.head(5)
Primeras filas del DataFrame:
| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | ... | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Intolerance: Love's Struggle Throughout the Ages | 1916.0 | Drama|History|War | NaN | USA | Not Rated | 123.0 | 1.33 | 385907.0 | NaN | ... | 436.0 | 22.0 | 9.0 | 481 | 691 | 1.0 | 10718 | 88.0 | 69.0 | 8.0 |
| 1 | Over the Hill to the Poorhouse | 1920.0 | Crime|Drama | NaN | USA | NaN | 110.0 | 1.33 | 100000.0 | 3000000.0 | ... | 2.0 | 2.0 | 0.0 | 4 | 0 | 1.0 | 5 | 1.0 | 1.0 | 4.8 |
| 2 | The Big Parade | 1925.0 | Drama|Romance|War | NaN | USA | Not Rated | 151.0 | 1.33 | 245000.0 | NaN | ... | 81.0 | 12.0 | 6.0 | 108 | 226 | 0.0 | 4849 | 45.0 | 48.0 | 8.3 |
| 3 | Metropolis | 1927.0 | Drama|Sci-Fi | German | Germany | Not Rated | 145.0 | 1.33 | 6000000.0 | 26435.0 | ... | 136.0 | 23.0 | 18.0 | 203 | 12000 | 1.0 | 111841 | 413.0 | 260.0 | 8.3 |
| 4 | Pandora's Box | 1929.0 | Crime|Drama|Romance | German | Germany | Not Rated | 110.0 | 1.33 | NaN | 9950.0 | ... | 426.0 | 20.0 | 3.0 | 455 | 926 | 1.0 | 7431 | 84.0 | 71.0 | 8.0 |
5 rows × 25 columns
# Mostrar las ultimas filas del DataFrame
print("Ultimas filas del DataFrame:")
df.tail(5)
Ultimas filas del DataFrame:
| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | ... | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5037 | War & Peace | NaN | Drama|History|Romance|War | English | UK | TV-14 | NaN | 16.00 | NaN | NaN | ... | 1000.0 | 888.0 | 502.0 | 4528 | 11000 | 1.0 | 9277 | 44.0 | 10.0 | 8.2 |
| 5038 | Wings | NaN | Comedy|Drama | English | USA | NaN | 30.0 | 1.33 | NaN | NaN | ... | 685.0 | 511.0 | 424.0 | 1884 | 1000 | 5.0 | 7646 | 56.0 | 19.0 | 7.3 |
| 5039 | Wolf Creek | NaN | Drama|Horror|Thriller | English | Australia | NaN | NaN | 2.00 | NaN | NaN | ... | 511.0 | 457.0 | 206.0 | 1617 | 954 | 0.0 | 726 | 6.0 | 2.0 | 7.1 |
| 5040 | Wuthering Heights | NaN | Drama|Romance | English | UK | NaN | 142.0 | NaN | NaN | NaN | ... | 27000.0 | 698.0 | 427.0 | 29196 | 0 | 2.0 | 6053 | 33.0 | 9.0 | 7.7 |
| 5041 | Yu-Gi-Oh! Duel Monsters | NaN | Action|Adventure|Animation|Family|Fantasy | Japanese | Japan | NaN | 24.0 | NaN | NaN | NaN | ... | 0.0 | NaN | NaN | 0 | 124 | 0.0 | 12417 | 51.0 | 6.0 | 7.0 |
5 rows × 25 columns
# Obtener las dimensiones del DataFrame
print("Dimensiones del DataFrame:")
print(df.shape)
Dimensiones del DataFrame: (5042, 25)
# Mostrar todas las columnas del DataFrame
print("Columnas del DataFrame:")
df.columns
Columnas del DataFrame:
Index(['Title', 'Year', 'Genres', 'Language', 'Country', 'Content Rating',
'Duration', 'Aspect Ratio', 'Budget', 'Gross Earnings', 'Director',
'Actor 1', 'Actor 2', 'Actor 3', 'Facebook Likes - Director',
'Facebook Likes - Actor 1', 'Facebook Likes - Actor 2',
'Facebook Likes - Actor 3', 'Facebook Likes - cast Total',
'Facebook likes - Movie', 'Facenumber in posters', 'User Votes',
'Reviews by Users', 'Reviews by Crtiics', 'IMDB Score'],
dtype='object')
# Valores nulos por columna
df.isnull().sum()
Title 0 Year 107 Genres 0 Language 13 Country 4 Content Rating 302 Duration 14 Aspect Ratio 328 Budget 491 Gross Earnings 883 Director 104 Actor 1 7 Actor 2 13 Actor 3 22 Facebook Likes - Director 104 Facebook Likes - Actor 1 7 Facebook Likes - Actor 2 13 Facebook Likes - Actor 3 22 Facebook Likes - cast Total 0 Facebook likes - Movie 0 Facenumber in posters 13 User Votes 0 Reviews by Users 20 Reviews by Crtiics 49 IMDB Score 0 dtype: int64
# Valores unicos por columnas
print("Valores unicos por columnas:")
df.nunique()
Valores unicos por columnas:
Title 4916 Year 91 Genres 914 Language 46 Country 65 Content Rating 18 Duration 191 Aspect Ratio 22 Budget 439 Gross Earnings 4035 Director 2397 Actor 1 2096 Actor 2 3031 Actor 3 3521 Facebook Likes - Director 435 Facebook Likes - Actor 1 878 Facebook Likes - Actor 2 917 Facebook Likes - Actor 3 906 Facebook Likes - cast Total 3978 Facebook likes - Movie 876 Facenumber in posters 19 User Votes 4826 Reviews by Users 954 Reviews by Crtiics 528 IMDB Score 78 dtype: int64
# Mostrar información del DataFrame
print("Información del DataFrame:")
df.info()
Información del DataFrame: <class 'pandas.core.frame.DataFrame'> RangeIndex: 5042 entries, 0 to 5041 Data columns (total 25 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Title 5042 non-null object 1 Year 4935 non-null float64 2 Genres 5042 non-null object 3 Language 5029 non-null object 4 Country 5038 non-null object 5 Content Rating 4740 non-null object 6 Duration 5028 non-null float64 7 Aspect Ratio 4714 non-null float64 8 Budget 4551 non-null float64 9 Gross Earnings 4159 non-null float64 10 Director 4938 non-null object 11 Actor 1 5035 non-null object 12 Actor 2 5029 non-null object 13 Actor 3 5020 non-null object 14 Facebook Likes - Director 4938 non-null float64 15 Facebook Likes - Actor 1 5035 non-null float64 16 Facebook Likes - Actor 2 5029 non-null float64 17 Facebook Likes - Actor 3 5020 non-null float64 18 Facebook Likes - cast Total 5042 non-null int64 19 Facebook likes - Movie 5042 non-null int64 20 Facenumber in posters 5029 non-null float64 21 User Votes 5042 non-null int64 22 Reviews by Users 5022 non-null float64 23 Reviews by Crtiics 4993 non-null float64 24 IMDB Score 5042 non-null float64 dtypes: float64(13), int64(3), object(9) memory usage: 984.9+ KB
# Calcular estadísticas descriptivas del DataFrame
print("Estadísticas descriptivas del DataFrame:")
df.describe()
Estadísticas descriptivas del DataFrame:
| Year | Duration | Aspect Ratio | Budget | Gross Earnings | Facebook Likes - Director | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4935.000000 | 5028.000000 | 4714.000000 | 4.551000e+03 | 4.159000e+03 | 4938.000000 | 5035.000000 | 5029.000000 | 5020.000000 | 5042.000000 | 5042.000000 | 5029.000000 | 5.042000e+03 | 5022.000000 | 4993.000000 | 5042.000000 |
| mean | 2002.470517 | 107.201074 | 2.220403 | 3.975262e+07 | 4.846841e+07 | 686.621709 | 6561.323932 | 1652.080533 | 645.009761 | 9700.959143 | 7527.457160 | 1.371446 | 8.368475e+04 | 272.770808 | 140.194272 | 6.442007 |
| std | 12.474599 | 25.197441 | 1.385113 | 2.061149e+08 | 6.845299e+07 | 2813.602405 | 15021.977635 | 4042.774685 | 1665.041728 | 18165.101925 | 19322.070537 | 2.013683 | 1.384940e+05 | 377.982886 | 121.601675 | 1.125189 |
| min | 1916.000000 | 7.000000 | 1.180000 | 2.180000e+02 | 1.620000e+02 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 5.000000e+00 | 1.000000 | 1.000000 | 1.600000 |
| 25% | 1999.000000 | 93.000000 | 1.850000 | 6.000000e+06 | 5.340988e+06 | 7.000000 | 614.500000 | 281.000000 | 133.000000 | 1411.250000 | 0.000000 | 0.000000 | 8.599250e+03 | 65.000000 | 50.000000 | 5.800000 |
| 50% | 2005.000000 | 103.000000 | 2.350000 | 2.000000e+07 | 2.551750e+07 | 49.000000 | 988.000000 | 595.000000 | 371.500000 | 3091.000000 | 166.000000 | 1.000000 | 3.437100e+04 | 156.000000 | 110.000000 | 6.600000 |
| 75% | 2011.000000 | 118.000000 | 2.350000 | 4.500000e+07 | 6.230944e+07 | 194.750000 | 11000.000000 | 918.000000 | 636.000000 | 13758.750000 | 3000.000000 | 2.000000 | 9.634700e+04 | 326.000000 | 195.000000 | 7.200000 |
| max | 2016.000000 | 511.000000 | 16.000000 | 1.221550e+10 | 7.605058e+08 | 23000.000000 | 640000.000000 | 137000.000000 | 23000.000000 | 656730.000000 | 349000.000000 | 43.000000 | 1.689764e+06 | 5060.000000 | 813.000000 | 9.500000 |
# Seleccionar una columna específica del DataFrame
print("Valores únicos de una columna específica:")
df['Year'].unique()
Valores únicos de una columna específica:
array([1916., 1920., 1925., 1927., 1929., 1930., 1932., 1933., 1934.,
1935., 1936., 1937., 1938., 1939., 1940., 1941., 1942., 1943.,
1944., 1945., 1946., 1947., 1948., 1949., 1950., 1951., 1952.,
1953., 1954., 1955., 1956., 1957., 1958., 1959., 1960., 1961.,
1962., 1963., 1964., 1965., 1966., 1967., 1968., 1969., 1970.,
1971., 1972., 1973., 1974., 1975., 1976., 1977., 1978., 1979.,
1980., 1981., 1982., 1983., 1984., 1985., 1986., 1987., 1988.,
1989., 1990., 1991., 1992., 1993., 1994., 1995., 1996., 1997.,
1998., 1999., 2000., 2001., 2002., 2003., 2004., 2005., 2006.,
2007., 2008., 2009., 2010., 2011., 2012., 2013., 2014., 2015.,
2016., nan])
# Obtener total de valores únicos de la columna específica
print("Total de valores únicos de una columna específica:")
df['Year'].nunique()
Total de valores únicos de una columna específica:
91
# Filtrar filas que cumplan una condición
print("Filtrar filas que cumplan una condición:")
filtered_df = df[df['Year'] > 2000]
filtered_df.head()
Filtrar filas que cumplan una condición:
| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | ... | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1509 | 15 Minutes | 2001.0 | Action|Crime|Drama|Thriller | English | USA | R | 120.0 | 2.35 | 42000000.0 | 24375436.0 | ... | 22000.0 | 9000.0 | 808.0 | 33585 | 748 | 1.0 | 42547 | 265.0 | 151.0 | 6.1 |
| 1510 | 3000 Miles to Graceland | 2001.0 | Action|Comedy|Crime|Thriller | English | USA | R | 125.0 | 2.35 | 42000000.0 | 15738632.0 | ... | 11000.0 | 904.0 | 867.0 | 14536 | 0 | 2.0 | 38076 | 399.0 | 113.0 | 5.9 |
| 1511 | A Beautiful Mind | 2001.0 | Biography|Drama | English | USA | PG-13 | 135.0 | 1.85 | 58000000.0 | 170708996.0 | ... | 1000.0 | 592.0 | 535.0 | 2827 | 29000 | 0.0 | 610568 | 1171.0 | 205.0 | 8.2 |
| 1512 | A Knight's Tale | 2001.0 | Action|Adventure|Romance | English | USA | PG-13 | 144.0 | 2.35 | 65000000.0 | 56083966.0 | ... | 13000.0 | 3000.0 | 996.0 | 18761 | 0 | 1.0 | 137003 | 658.0 | 167.0 | 6.9 |
| 1513 | A.I. Artificial Intelligence | 2001.0 | Adventure|Drama|Sci-Fi | English | USA | PG-13 | 146.0 | 1.85 | 100000000.0 | 78616689.0 | ... | 3000.0 | 882.0 | 681.0 | 6217 | 11000 | 0.0 | 238747 | 2153.0 | 281.0 | 7.1 |
5 rows × 25 columns
# Contar valores de una columan específica
print("Conteo de los distintos lenguaje de las peliculas:")
df['Language'].value_counts()
Conteo de los distintos lenguaje de las peliculas:
Language English 4704 French 73 Spanish 40 Hindi 28 Mandarin 26 German 19 Japanese 18 Cantonese 11 Italian 11 Russian 11 Portuguese 8 Korean 8 Hebrew 5 Swedish 5 Danish 5 Arabic 5 Polish 4 Persian 4 Norwegian 4 Dutch 4 Thai 3 Chinese 3 Romanian 2 Zulu 2 Icelandic 2 Aboriginal 2 Dari 2 Indonesian 2 Swahili 1 Telugu 1 Slovenian 1 Urdu 1 Panjabi 1 Kannada 1 Kazakh 1 Bosnian 1 Greek 1 Mongolian 1 Vietnamese 1 Czech 1 Maya 1 Filipino 1 Hungarian 1 Aramaic 1 Dzongkha 1 Tamil 1 Name: count, dtype: int64
# Ordenar el DataFrame por una columna específica
print("Ordenar el DataFrame por una columna específica:")
sorted_df = df.sort_values(by='Title', ascending=False)
sorted_df.head()
Ordenar el DataFrame por una columna específica:
| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | ... | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2293 | Æon Flux | 2005.0 | Action|Sci-Fi | English | USA | PG-13 | 93.0 | 2.35 | 62000000.0 | 25857987.0 | ... | 9000.0 | 460.0 | 352.0 | 10185 | 0 | 0.0 | 110614 | 532.0 | 178.0 | 5.5 |
| 1905 | xXx | 2002.0 | Action|Adventure|Thriller | English | USA | PG-13 | 132.0 | 2.35 | 70000000.0 | 141204016.0 | ... | 14000.0 | 223.0 | 212.0 | 14790 | 10000 | 0.0 | 142569 | 737.0 | 191.0 | 5.8 |
| 2508 | xXx: State of the Union | 2005.0 | Action|Adventure|Crime|Thriller | English | USA | PG-13 | 101.0 | 2.35 | 87000000.0 | 26082914.0 | ... | 287.0 | 233.0 | 218.0 | 993 | 0 | 2.0 | 51349 | 213.0 | 77.0 | 4.3 |
| 1223 | eXistenZ | 1999.0 | Horror|Sci-Fi|Thriller | English | Canada | R | 115.0 | 1.85 | 31000000.0 | 2840417.0 | ... | 1000.0 | 900.0 | 716.0 | 2990 | 6000 | 0.0 | 77493 | 527.0 | 196.0 | 6.8 |
| 2749 | [Rec] | 2007.0 | Horror | Spanish | Spain | R | 78.0 | 1.85 | 1500000.0 | NaN | ... | 120.0 | 9.0 | 7.0 | 145 | 15000 | 0.0 | 131462 | 374.0 | 252.0 | 7.5 |
5 rows × 25 columns
apply command
# Aplicar una función lambda a cada entrada de la columna 'Genres' para contar el número de géneros en cada entrada
total_generos = df['Genres'].apply(lambda x: len(x.split('|')))
# Imprimir el máximo valor entre todos los conteos de géneros
print("Máximo número de géneros en una entrada:", max(total_generos))
Máximo número de géneros en una entrada: 8
Working with duplicates
# Contar el número de filas duplicadas en el DataFrame
num_filas_duplicadas = df.duplicated().sum()
print("Número de filas duplicadas en el DataFrame:", num_filas_duplicadas)
Número de filas duplicadas en el DataFrame: 45
# Eliminar filas duplicadas del DataFrame
df = df.drop_duplicates()
num_filas_duplicadas = df.duplicated().sum()
print("Número de filas duplicadas en el DataFrame:", num_filas_duplicadas)
Número de filas duplicadas en el DataFrame: 0
Create new columns
import math
# Redondear cada valor de la columna 'Duration' al múltiplo de 30 más cercano
df['DurationRounded'] = df['Duration'].fillna(0).apply(lambda x: math.ceil(x / 30) * 30)
# Imprimir valores
df['DurationRounded'].unique()
array([150, 120, 180, 90, 240, 210, 270, 30, 300, 330, 60, 0, 360,
540], dtype=int64)
# Función para obtener la década correspondiente
def obtener_decada(year):
if year < 1900:
return None
elif year < 2000:
return '1900'
elif year < 2010:
return '2000'
else:
return '2010'
# Aplicar la función a la columna 'Year' para crear la nueva columna 'Decade'
df['Decade'] = df['Year'].fillna(0).apply(obtener_decada)
# Imprimir valores
df['Decade'].unique()
array(['1900', '2000', '2010', None], dtype=object)
# Definición de los intervalos
bins = [0, 5, 7, 10]
# Definición de las etiquetas
labels = ['Bajo', 'Medio', 'Alto']
# Aplicación de la función pd.cut() para crear la nueva columna
df['IMDB Score Category'] = pd.cut(df['IMDB Score'], bins=bins, labels=labels)
# Imprimir valores
df['IMDB Score Category'].unique()
['Alto', 'Bajo', 'Medio'] Categories (3, object): ['Bajo' < 'Medio' < 'Alto']
# Definir el diccionario de países y continentes
continentes_por_pais = {
'USA': 'North America',
'Germany': 'Europe',
'Japan': 'Asia',
'Denmark': 'Europe',
'UK': 'Europe',
'Italy': 'Europe',
'France': 'Europe',
'West Germany': 'Europe',
'Sweden': 'Europe',
'Soviet Union': 'Europe',
'Iran': 'Asia',
'Australia': 'Oceania',
'Libya': 'Africa',
'Canada': 'North America',
'South Korea': 'Asia',
'Brazil': 'South America',
'Netherlands': 'Europe',
'China': 'Asia',
'Norway': 'Europe',
'Switzerland': 'Europe',
'New Zealand': 'Oceania',
'Hong Kong': 'Asia',
'Peru': 'South America',
'India': 'Asia',
'Spain': 'Europe',
'Aruba': 'North America',
'Mexico': 'North America',
'Czech Republic': 'Europe',
'Taiwan': 'Asia',
'Argentina': 'South America',
'Thailand': 'Asia',
'New Line': 'North America',
'Afghanistan': 'Asia',
'Russia': 'Europe',
'Ireland': 'Europe',
'Colombia': 'South America',
'Romania': 'Europe',
'Philippines': 'Asia',
'Hungary': 'Europe',
'Cameroon': 'Africa',
'South Africa': 'Africa',
'Israel': 'Asia',
'Poland': 'Europe',
'Turkey': 'Asia',
'Slovakia': 'Europe',
'Greece': 'Europe',
'Iceland': 'Europe',
'Official site': None,
'Georgia': 'Europe',
'Finland': 'Europe',
'Belgium': 'Europe',
'Indonesia': 'Asia',
'Nigeria': 'Africa',
'Dominican Republic': 'North America',
'United Arab Emirates': 'Asia',
'Egypt': 'Africa',
'Bulgaria': 'Europe',
'Bahamas': 'North America',
'Cambodia': 'Asia',
'Kyrgyzstan': 'Asia',
'Kenya': 'Africa',
'Slovenia': 'Europe',
'Pakistan': 'Asia',
'Chile': 'South America',
'Panama': 'North America'
}
# Crear una nueva columna 'Continent' basada en el diccionario de países y continentes
df['Continent'] = df['Country'].map(continentes_por_pais)
# Imprimir valores
df['Continent'].unique()
array(['North America', 'Europe', 'Asia', 'Oceania', 'Africa',
'South America', None, nan], dtype=object)
Operations with GroupBy¶

# Agrupar por el año y calcular la media de IMDB Score
df_grouped_year = df.groupby('Year')['IMDB Score'].mean()
df_grouped_year
Year
1916.0 8.000000
1920.0 4.800000
1925.0 8.300000
1927.0 8.300000
1929.0 7.150000
...
2012.0 6.263303
2013.0 6.366949
2014.0 6.239516
2015.0 6.041441
2016.0 6.376699
Name: IMDB Score, Length: 91, dtype: float64
# Agrupar por año y país y calcular la suma de User Votes
df_grouped_year_country = df.groupby(['Year', 'Country'])['User Votes'].sum()
df_grouped_year_country
Year Country
1916.0 USA 10718
1920.0 USA 5
1925.0 USA 4849
1927.0 Germany 111841
1929.0 Germany 7431
...
2016.0 Mexico 368
Panama 178
South Korea 2469
UK 529795
USA 2926518
Name: User Votes, Length: 496, dtype: int64
# Agrupar por año y calcular varias estadísticas para IMDB Score
df_grouped_year_stats = df.groupby('Year')['IMDB Score'].agg(['mean', 'median', 'std'])
df_grouped_year_stats
| mean | median | std | |
|---|---|---|---|
| Year | |||
| 1916.0 | 8.000000 | 8.00 | NaN |
| 1920.0 | 4.800000 | 4.80 | NaN |
| 1925.0 | 8.300000 | 8.30 | NaN |
| 1927.0 | 8.300000 | 8.30 | NaN |
| 1929.0 | 7.150000 | 7.15 | 1.202082 |
| ... | ... | ... | ... |
| 2012.0 | 6.263303 | 6.40 | 1.101834 |
| 2013.0 | 6.366949 | 6.50 | 1.107042 |
| 2014.0 | 6.239516 | 6.30 | 1.137603 |
| 2015.0 | 6.041441 | 6.20 | 1.257374 |
| 2016.0 | 6.376699 | 6.40 | 1.171659 |
91 rows × 3 columns
# Definir una función personalizada para calcular la diferencia entre el máximo y el mínimo de User Votes
def custom_function(x):
return x.max() - x.min()
# Agrupar por país y aplicar la función personalizada a User Votes
df_grouped_country_custom = df.groupby('Country')['User Votes'].agg(custom_function)
df_grouped_country_custom
Country
Afghanistan 0
Argentina 131059
Aruba 0
Australia 552204
Bahamas 0
...
Turkey 0
UK 641990
USA 1689759
United Arab Emirates 0
West Germany 167251
Name: User Votes, Length: 65, dtype: int64
# Dividir IMDB Score en intervalos y contar el número de películas en cada intervalo
bins = [0, 5, 7, 10]
labels = ['Bajo', 'Medio', 'Alto']
df['IMDB Score Category'] = pd.cut(df['IMDB Score'], bins=bins, labels=labels)
df_grouped_imdb_category_count = df.groupby('IMDB Score Category').size()
df_grouped_imdb_category_count
C:\Users\franc\AppData\Local\Temp\ipykernel_9492\3266498935.py:5: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
df_grouped_imdb_category_count = df.groupby('IMDB Score Category').size()
IMDB Score Category Bajo 519 Medio 2902 Alto 1576 dtype: int64
Pivot Tables¶
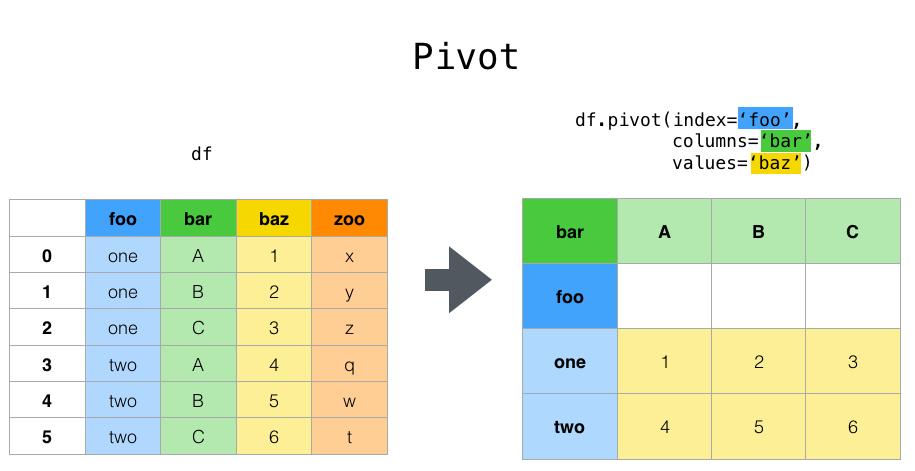
# Crear una pivot table para calcular la suma de User Votes según el año y el país
pivot_table_basic = df.pivot_table(values='User Votes', index='Decade', columns='Continent', aggfunc='mean')
pivot_table_basic
| Continent | Africa | Asia | Europe | North America | Oceania | South America |
|---|---|---|---|---|---|---|
| Decade | ||||||
| 1900 | 9852.00 | 53425.176471 | 65021.528205 | 90449.414299 | 52702.550000 | 26603.666667 |
| 2000 | 135941.75 | 42659.703125 | 74180.805774 | 87934.669375 | 123325.576923 | 102688.250000 |
| 2010 | 12990.75 | 23182.250000 | 64646.487395 | 91536.211990 | 99622.409091 | 7807.750000 |
# Crear una pivot table para calcular la media de IMDB Score según el año y el Content Rating
pivot_table_mean = df.pivot_table(values='IMDB Score', index='DurationRounded', columns='Country', aggfunc='mean').fillna(0)
pivot_table_mean
| Country | Afghanistan | Argentina | Aruba | Australia | Bahamas | Belgium | Brazil | Bulgaria | Cambodia | Cameroon | ... | Spain | Sweden | Switzerland | Taiwan | Thailand | Turkey | UK | USA | United Arab Emirates | West Germany |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DurationRounded | |||||||||||||||||||||
| 0 | 0.0 | 0.0 | 0.0 | 7.100000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 7.366667 | 5.883333 | 0.0 | 0.0 |
| 30 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 7.950000 | 7.059259 | 0.0 | 0.0 |
| 60 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 7.675000 | 7.505556 | 0.0 | 0.0 |
| 90 | 7.4 | 7.2 | 0.0 | 6.318182 | 0.0 | 6.300000 | 5.500000 | 0.0 | 0.0 | 0.0 | ... | 6.525000 | 8.10 | 0.0 | 0.00 | 0.00 | 0.0 | 6.307500 | 5.886128 | 8.2 | 6.0 |
| 120 | 0.0 | 7.3 | 4.8 | 6.450000 | 4.4 | 5.366667 | 7.333333 | 6.1 | 5.6 | 7.5 | ... | 6.834783 | 8.05 | 5.9 | 7.15 | 5.95 | 0.0 | 6.690262 | 6.252962 | 0.0 | 7.4 |
| 150 | 0.0 | 8.2 | 0.0 | 7.100000 | 0.0 | 0.000000 | 8.700000 | 0.0 | 0.0 | 0.0 | ... | 6.983333 | 7.15 | 0.0 | 0.00 | 0.00 | 6.0 | 7.031373 | 6.911661 | 0.0 | 0.0 |
| 180 | 0.0 | 0.0 | 0.0 | 6.600000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 7.592308 | 7.420000 | 0.0 | 0.0 |
| 210 | 0.0 | 0.0 | 0.0 | 7.400000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 8.150000 | 7.679167 | 0.0 | 0.0 |
| 240 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 8.233333 | 7.533333 | 0.0 | 0.0 |
| 270 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 6.60 | 0.0 | 0.00 | 0.00 | 0.0 | 7.000000 | 0.000000 | 0.0 | 0.0 |
| 300 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 6.60 | 0.0 | 0.000000 | 7.600000 | 0.0 | 8.4 |
| 330 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 0.000000 | 7.400000 | 0.0 | 0.0 |
| 360 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 |
| 540 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | ... | 0.000000 | 0.00 | 0.0 | 0.00 | 0.00 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 |
14 rows × 65 columns