Introducción¶
¿Qué es el Machine learning?¶
Podemos resumir Machine Learning en cuatro puntos:
Estudia y construye sistemas que pueden aprender de los datos, más que seguir instrucciones explícitamente programadas.
Conjunto de técnicas y modelos que permiten el modelamiento predictivo de datos, reunidas a partir de la intersección de elementos de probabilidad, estadística e inteligencia artificial.
Típicamente, alguien que trabaja en Machine Learning está en la Academia y busca realizar investigación y publicar artículos.
Pregunta fundamental: ¿Qué conocimiento emerge a partir de los datos? ¿Qué modelo/técnica otorga la mejor predicción para estos datos?
Para poder avanzar en el estudio de machine learning es de vital importancia definir el concepto de modelo.
¿Qué se entiende por modelo?¶
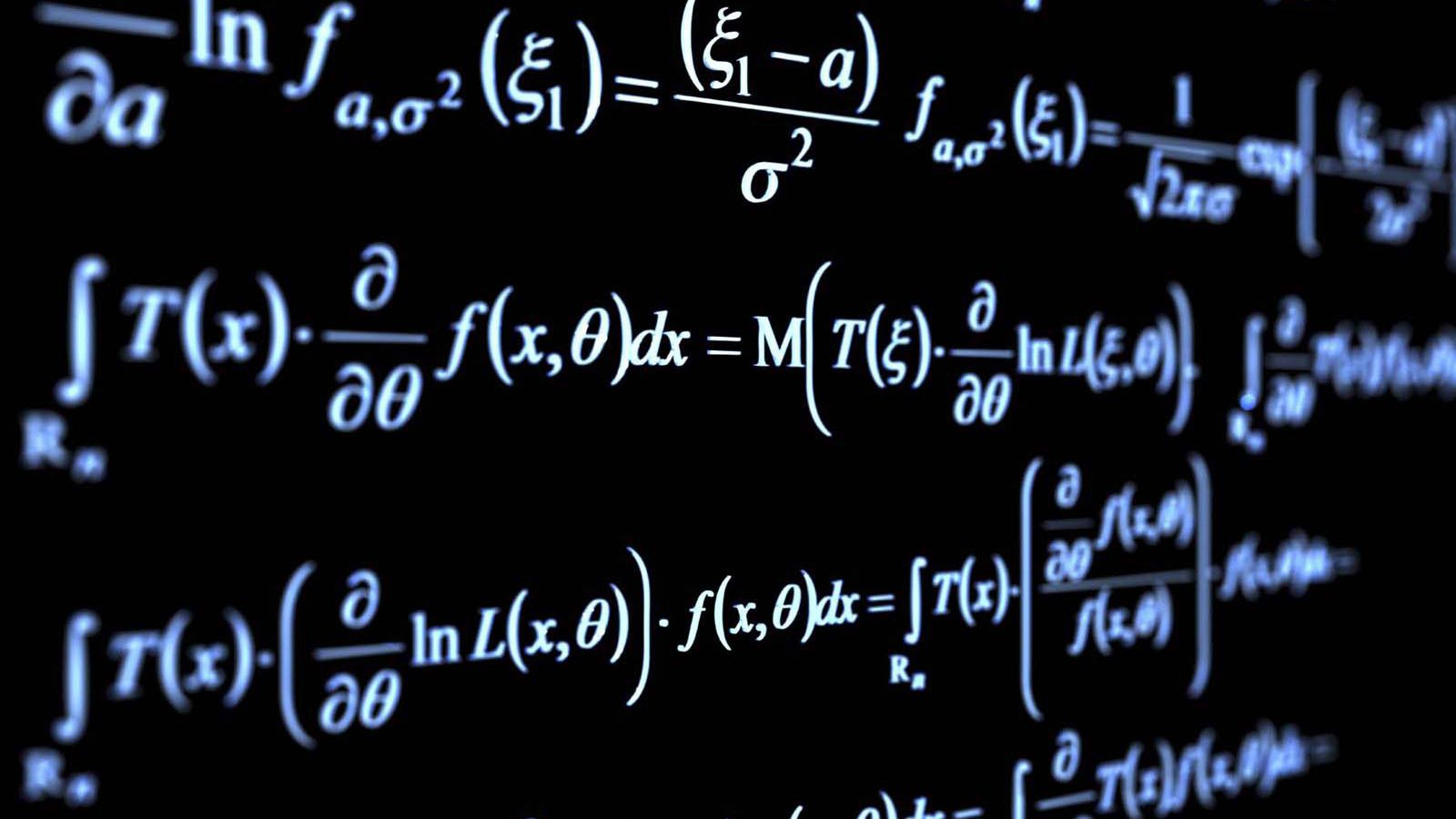
Un modelo se entinde como:
- Una representación abstracta y conveniente de un sistema.
- Una simplificación del mundo real.
- Un medio de exploración y de explicación para nuestro entendimiento de la realidad.
Por otro lado, un modelo no es:
- Igual al mundo real.
- Un sustituto para mediciones o experimentos.
Los modelos nos permiten:
- reproducir experimentos donde factores no pueden ser fácilmente controlados.
- Ejemplo: Comportamiento de cápsula lunar en gravedad cero y al atravesar atmósfera a gran velocidad.
- simplificar el entendimiento de sistemas complejos, al permitir el análisis y exploración de cada componente del sistema por separado.
- Ejemplo: Adelgazamiento de la capa de hielo polar por calentamiento global.
¿ Qué tipos de problemas podemos abordar con machine learning?¶
Los problemas que se pueden resolver con machine learning se pueden englobar en tres tipos: aprendeizaje supervisado, aprendizaje no supervisado y aprendizaje reforzado.

Aprendizaje supervisado¶
- El sistema aprende en base a datos estructurados o no estructurados.
- Clasificados previamente (se conoce la respuesta).
- El algoritmo produce una función que establece una correspondencia entre las entradas y las salidas deseadas del sistema.
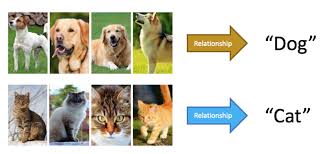
Aprendizaje no supervisado¶
- Modelo se construye usando un conjunto de datos como entrada, los cuales no han sido clasificados previamente.
- El sistema tiene que ser capaz de reconocer patrones para poder etiquetar las nuevas entradas.
Aprendizaje por refuerzo¶
Aprendizaje por refuerzo o Aprendizaje reforzado es un área del aprendizaje automático inspirada en la psicología conductista, cuya ocupación es determinar qué acciones debe escoger un agente de software en un entorno dado con el fin de maximizar alguna noción de "recompensa" o premio acumulado.

Algoritmos más utilizados¶
Los algoritmos que más se suelen utilizar en los problemas de Machine Learning son los siguientes:
¿ Qué se necesita para aprender machine learning?
Se necesita tener conocimientos de los siguientes tópicos.
- Algebra Lineal
- Probabilidad y estadística
- Optimización
Librerías de machine learning en python¶
Una de las grandes ventajas que ofrece python sobre otros lenguajes de programación; es lo grande y prolifera que es la comunidad de desarrolladores que lo rodean; comunidad que ha contribuido con una gran variedad de librerías de primer nivel que extienden la funcionalidades del lenguaje. Para el caso de Machine Learning , las principales librerías que podemos utilizar son:
Scikit-Learn¶

Scikit-learn es la principal librería que existe para trabajar con Machine Learning, incluye la implementación de un gran número de algoritmos de aprendizaje. La podemos utilizar para clasificaciones, extraccion de características, regresiones, agrupaciones, reducción de dimensiones, selección de modelos, o preprocesamiento.
Statsmodels¶

Statsmodels es otra gran librería que hace foco en modelos estadísticos y se utiliza principalmente para análisis predictivos y exploratorios. Las pruebas estadísticas que ofrece son bastante amplias y abarcan tareas de validación para la mayoría de los casos.
Conceptos claves en machine learning¶
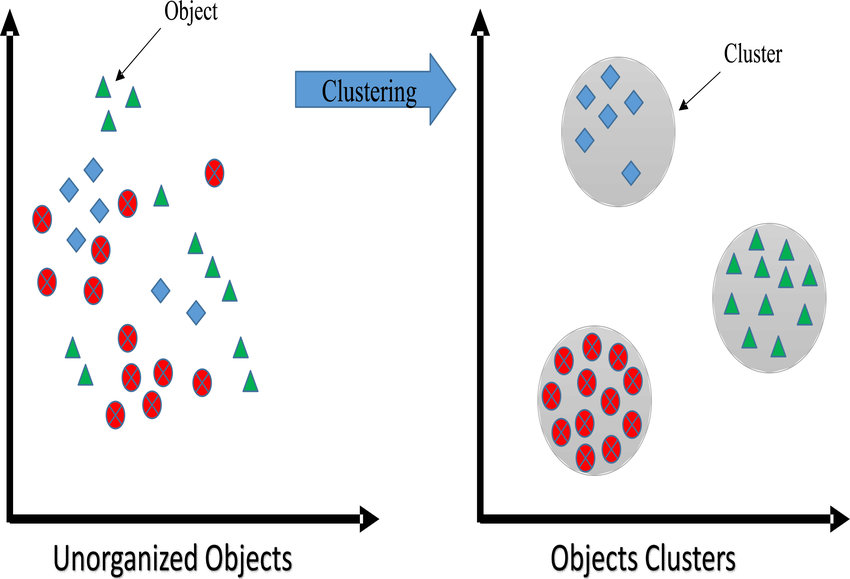
Esquema machine learning¶
EL proceso de machine learning se puede resumir a grandes rasgo por el siguiente esquema.
- Recolectar los datos. Podemos recolectar los datos desde muchas fuentes, podemos por ejemplo extraer los datos de un sitio web o obtener los datos utilizando una API o desde una base de datos.
- Preprocesar los datos. Es prácticamente inevitable tener que realizar varias tareas de preprocesamiento antes de poder utilizar los datos. Igualmente este punto suele ser mucho más sencillo que el paso anterior.
- Explorar los datos. Una vez que ya tenemos los datos y están con el formato correcto, podemos realizar un pre análisis para corregir los casos de valores faltantes o intentar encontrar a simple vista algún patrón en los mismos que nos facilite la construcción del modelo.
- Entrenar el modelo. En esta etapa se entrenan los modelos con los datos que venimos procesando en las etapas anteriores. La idea es que los modelos puedan extraer información útil de los datos que le pasamos para luego poder hacer predicciones.
- Evaluar el modelo. Evaluamos que tan preciso es el modelo en sus predicciones y si no estamos muy conforme con su rendimiento, podemos volver a la etapa anterior y continuar entrenando el modelo cambiando algunos parámetros hasta lograr un rendimiento aceptable.
- Utilizar el modelo. En esta ultima etapa, ya ponemos a nuestro modelo a enfrentarse al problema real. Aquí también podemos medir su rendimiento, lo que tal vez nos obligue a revisar todos los pasos anteriores.
Los pasos 1,2,3 son los pasos que ya se han visto con detalle en este curso. Por otro lado, la etapa de modelamiento (entrenar, evaluar y predecir) será necesario introducir nuevos conceptos.