![]()
Series Temporales¶
Introducción¶
- Una serie temporal o cronológica es una sucesión de datos medidos en determinados momentos y ordenados cronológicamente. Los datos pueden estar espaciados a intervalos iguales (como la temperatura en un observatorio meteorológico en días sucesivos al mediodía) o desiguales (como el peso de una persona en sucesivas mediciones en el consultorio médico, la farmacia, etc.).
- Uno de los usos más habituales de las series de datos temporales es su análisis para predicción y pronóstico (así se hace por ejemplo con los datos climáticos, las acciones de bolsa, o las series de datos demográficos). Resulta difícil imaginar una rama de las ciencias en la que no aparezcan datos que puedan ser considerados como series temporales. Las series temporales se estudian en estadística, procesamiento de señales, econometría y muchas otras áreas.
Análisis de series temporales¶
Para entender mejor el comportamiento de una serie temporal, nos iremos ayudando con python.
Descripción del problema¶
El conjunto de datos se llama AirPassengers.csv, el cual contiene la información del total de pasajeros (a nivel de mes) entre los año 1949 y 1960.
En terminos estadísticos, el problema puede ser presentado por la serie temporal $\left \{ X_t: t \in T \right \}$ , donde:
- $X_{t}$: corresponde al total de pasajeros en el tiempo t
- $t$: tiempo medido a nivel de mes.
Comparando la serie temporal con un dataframe, este sería un dataframe de una sola columna, en cuyo índice se encuentra las distintas fechas.
El objetivo es poder desarrollar un modelo predictivo que me indique el número de pasajeros para los próximos dos años. Antes de ajustar el modelo, se debe entender el comportamiento de la serie de tiempo en estudio y con esta información, encontrar el modelo que mejor se puede ajustar (en caso que exista).
Como son muchos los conceptos que se presentarán, es necesario ir apoyandose con alguna herramienta de programación, en nuestro caso python. Dentro de python, la librería statsmodels es ideal para hacer este tipo de análisis.
Lo primero es cargar, transformar y visualizar el conjunto de datos.
# librerias
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# graficos incrustados
plt.style.use('fivethirtyeight')
%matplotlib inline
# parametros esteticos de seaborn
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (12, 4)})
# cargar datos
df = pd.read_csv(
'https://raw.githubusercontent.com/fralfaro/MAT281_2022/main/docs/lectures/ml/time_series/data/AirPassengers.csv',
sep=","
)
df.columns = ['date','passengers']
df.head()
| date | passengers | |
|---|---|---|
| 0 | 1949-01 | 112 |
| 1 | 1949-02 | 118 |
| 2 | 1949-03 | 132 |
| 3 | 1949-04 | 129 |
| 4 | 1949-05 | 121 |
# resumen
df.describe()
| passengers | |
|---|---|
| count | 144.000000 |
| mean | 280.298611 |
| std | 119.966317 |
| min | 104.000000 |
| 25% | 180.000000 |
| 50% | 265.500000 |
| 75% | 360.500000 |
| max | 622.000000 |
# fechas
print('Fecha Inicio: {}\nFecha Fin: {}'.format(df.date.min(),df.date.max()))
Fecha Inicio: 1949-01 Fecha Fin: 1960-12
# formato datetime de las fechas
df['date'] = pd.to_datetime(df['date'], format='%Y-%m')
# dejar en formato ts
y = df.set_index('date').resample('M').mean()
y.head()
| passengers | |
|---|---|
| date | |
| 1949-01-31 | 112.0 |
| 1949-02-28 | 118.0 |
| 1949-03-31 | 132.0 |
| 1949-04-30 | 129.0 |
| 1949-05-31 | 121.0 |
# graficar datos
y.plot(figsize=(15, 3),color = 'blue')
plt.show()

Basado en el gráfico, uno podria decir que tiene un comportamiento estacionario en el tiempo, es decir, que se repita cada cierto instante de tiempo. Además, la demanda ha tendido a incrementar año a año.
Por otro lado, podemos agregar valor a nuestro entendimiento de nuestra serie temporal, realizando un diagrama de box-plot a los distintos años.
# diagrama de caja y bigotes
fig, ax = plt.subplots(figsize=(15,6))
sns.boxplot(y.passengers.index.year, y.passengers, ax=ax)
plt.show()
C:\Users\franc\AppData\Local\pypoetry\Cache\virtualenvs\docs-rzB-GL7Y-py3.8\lib\site-packages\seaborn\_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation. warnings.warn(

Descomposición STL¶
Una serie temporal la podemos descomponer en tres componentes:
- tendencia ($T$): trayectoria de los datos en el tiempo (dirección positiva o negativa).
- estacionalidad($S$): fluctuaciones regulares y predecibles en un periodo determinado (anual, semestral,etc.)
- ruido($e$): error intrínsico al tomar una serie temporal (instrumenos, medición humana, etc.)
Cuando un descompone la serie temporla en sus tres componenctes (tendencia, estacionalidad, ruido) se habla de descompocisión STL. En muchas ocasiones no es posible descomponer adecuadamente la serie temporal, puesto que la muestra obtenida no presenta un comportamiento ciclico o repetitivo en el periodo de tiempo analizado.
Por otro lado, esta descomposición se puede realizar de dos maneras diferentes:
- Aditiva: $$X_{t} = T_{t} + S_{t} + e_{t}$$
- Multiplicativa: $$X_{t} = T_{t} * S_{t} * e_{t}$$
Por suepuesto esta no es la única forma de descomponer una serie, pero sirve como punto de partida para comprender nuestra serie en estudio.
Realizaremos un descomposición del tipo multiplicativa, ocupando el comando de statsmodels seasonal_decompose.
from pylab import rcParams
import statsmodels.api as sm
import matplotlib.pyplot as plt
rcParams['figure.figsize'] = 18, 8
decomposition = sm.tsa.seasonal_decompose(y, model='multiplicative')
fig = decomposition.plot()
plt.show()

Analicemos cada uno de estos gráficos:
- gráfico 01 (serie original): este gráfico simplemente nos muestra la serie original graficada en el tiempo.
- gráfico 02 (tendencia): este gráfico nos muestra la tendencia de la serie, para este caso, se tiene una tendencial lineal positiva.
- gráfico 03 (estacionariedad): este gráfico nos muestra la estacionariedad de la serie, para este caso, se muestra una estacionariedad año a año, esta estacionariedad se puede ver como una curva invertida (función cuadrática negativa), en donde a aumenta hasta hasta a mediados de años (o un poco más) y luego esta cae suavemente a final de año.
- gráfico 04 (error): este gráfico nos muestra el error de la serie, para este caso, el error oscila entre 0 y 1. En general se busca que el error sea siempre lo más pequeño posible y que tenga el comportamiento de una distribución normal. Cuando el error sigue una distribución normal con media cero y varianza 1, se dice que el error es un ruido blanco.
¿ cómo es un ruido blanco?, mostremos un ruido blanco en python y veamos como este luce:
# grafico: lineplot
np.random.seed(42) # fijar semilla
mean = 0
std = 1
num_samples = 300
samples = np.random.normal(mean, std, size=num_samples)
plt.plot(samples)
plt.title("Ruido blanco: N(0,1)")
plt.show()

Observemos que el ruido blanco oscila sobre el valor 0 y tiene una varianza constante (igual a 1).
Veamos su histograma:
# grafico: histograma
plt.hist(samples,bins = 10)
plt.title("Ruido blanco: N(0,1)")
plt.show()

EL histograma de una variable normal, se caracteriza por esa forma de campana simétrica entorno a un valor, en este caso, entorno al valor 0.
Series Estacionarias¶
Un concepto importante para el ánalisis de series temporales, es el concepto de estacionariedad.
Definición¶
Sea $\left \{ X_t: t \in T \right \}$ una serie temporal. Se dice que una serie temporal es débilmente estacionaria si:
- $\mathbb{V}(X_t) < \infty$, para todo $t \in T$.
- $\mu_{X}(t)= \mu$, para todo $t \in T$.
- $\gamma_{X}(r,s)= \gamma_{X}(r+h,s+h)=\gamma_{X}(h) $, para todo $r,s,h\in T$.
En palabras simple, una serie temporal es débilmente estacionaria si varía poco respecto a su propia media.
Veamos las siguientes imágenes:
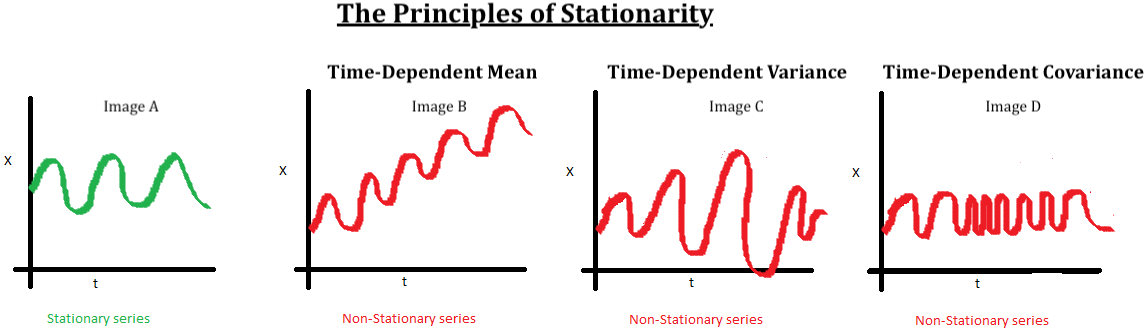
La imagen A: Este es un excelente ejemplo de una serie estacionaria, a simple vista se puede ver que los valores se encuentran oscilando en un rango acotado (tendencia constante) y la variabilidad es constante.
Las imágenes B, C y D no son estacionarias porque:
- imagen B: existe una una tendencia no contante, para este caso lineal (similar al caso que estamos analizando).
imagen C: existe varianza no constante, si bien varia dentro de valores acotados, la oscilaciones son erráticas.
imagen D: existe codependencia entre los distintos instantes de tiempo.
¿ Por qué es importante este concepto ?
- Supuesto base de muchos modelos de series temporales (desde el punto de vista estadístico)
- No se requiere muchas complicaciones extras para que las predicciones sean "buenas".
Formas de detectar la estacionariedad¶
La manera más simple es gráficarla e inferir el comportamiento de esta. La ventaja que este método es rápido, sin embargo, se encuentra sesgado por el criterio del ojo humano.
Por otro lado existen algunas alternativas que aquí presentamos:
Autocorrelación (ACF) y autocorrelación parcial PACF
Definamos a grandes rasgos estos conceptos:
- Función de autocorrelación (ACF). En el retardo $k$, es la autocorrelación entre los valores de las series que se encuentran a $k$ intervalos de distancia.
- Función de autocorrelación parcial (PACF). En el retardo $k$, es la autocorrelación entre los valores de las series que se encuentran a $k$ intervalos de distancia, teniendo en cuenta los valores de los intervalos intermedios.
Si la serie temporal es estacionaria, los gráficos ACF / PACF mostrarán una rápida disminución de la correlación después de un pequeño retraso entre los puntos.
Gráfiquemos la acf y pacf de nuestra serie temporal ocupando los comandos plot_acf y plot_pacf, respectivamente.
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
pyplot.figure(figsize=(12,9))
# acf
pyplot.subplot(211)
plot_acf(y.passengers, ax=pyplot.gca(), lags = 30)
#pacf
pyplot.subplot(212)
plot_pacf(y.passengers, ax=pyplot.gca(), lags = 30)
pyplot.show()
C:\Users\franc\AppData\Local\pypoetry\Cache\virtualenvs\docs-rzB-GL7Y-py3.8\lib\site-packages\statsmodels\graphics\tsaplots.py:348: FutureWarning: The default method 'yw' can produce PACF values outside of the [-1,1] interval. After 0.13, the default will change tounadjusted Yule-Walker ('ywm'). You can use this method now by setting method='ywm'.
warnings.warn(

Se observa de ambas imagenes, que estas no decaen rápidamente a cero, por lo cual se puede decir que la serie en estudio no es estacionaria.
Prueba Dickey-Fuller
En estadística, la prueba Dickey-Fuller prueba la hipótesis nula de que una raíz unitaria está presente en un modelo autorregresivo. La hipótesis alternativa es diferente según la versión de la prueba utilizada, pero generalmente es estacionariedad o tendencia-estacionaria. Lleva el nombre de los estadísticos David Dickey y Wayne Fuller, quienes desarrollaron la prueba en 1979.
Para efectos práticos, para el caso de estacionariedad se puede definir el test como:
- Hipótesis nula: la serie temporal no es estacionaria.
- Hipótesis alternativa: la serie temporal es alternativa.
Rechazar la hipótesis nula (es decir, un valor p muy bajo) indicará estacionariedad
from statsmodels.tsa.stattools import adfuller
#test Dickey-Fulle:
print ('Resultados del test de Dickey-Fuller:')
dftest = adfuller(y.passengers, autolag='AIC')
dfoutput = pd.Series(dftest[0:4],
index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
print(dfoutput)
Resultados del test de Dickey-Fuller: Test Statistic 0.815369 p-value 0.991880 #Lags Used 13.000000 Number of Observations Used 130.000000 dtype: float64
Dado que el p-value es 0.991880, se concluye que la serie temporal no es estacionaria.
¿ Qué se puede hacer si la serie no es etacionaria ?
Nuestro caso en estudio resulto ser una serie no estacionaria, no obstante, se pueden realizar tranformaciones para solucionar este problema.
Como es de esperar, estas tranformaciones deben cumplir ciertas porpiedades (inyectividad, diferenciables, etc.). A continuación, se presentan algunas de las tranformaciones más ocupadas en el ámbito de series temporales:
Sea $X_{t}$ una serie temporal, entonces uno puede definir una nueva serie temporal $Y_{t}$ de la siguiente manera:
- diferenciación: $Y_{t} =\Delta X_{t} =X_{t}-X_{t-1}$.
- transformaciones de Box-Cox:
$$Y_{t} = \left\{\begin{matrix} \dfrac{X_{t}^{\lambda}-1}{\lambda}, \ \ \textrm{si } \lambda > 0\\ \textrm{log}(X_{t}), \ \ \textrm{si } \lambda = 0 \end{matrix}\right.$$
Ayudemonos con python para ver el resultado de las distintas transformaciones.
# diferenciacion
Y_diff = y.diff()
rcParams['figure.figsize'] = 12, 4
plt.plot(Y_diff)
plt.title("Serie diferenciada")
plt.show()

def box_transformations(y,param):
if param>0:
return y.apply(lambda x: (x**(param)-1)/param)
elif param==0:
return np.log(y)
else:
print("lambda es negativo, se devulve la serie original")
return y
# logaritmo
Y_log = box_transformations(y,0)
rcParams['figure.figsize'] = 12, 4
plt.plot(Y_log)
plt.title("Serie logaritmica")
plt.show()

# cuadratica
Y_quad = box_transformations(y,2)
rcParams['figure.figsize'] = 12, 4
plt.plot(Y_log)
plt.title("Serie cuadratica")
plt.show()

Modelos de forecast (Pronóstico)¶
Para realizar el pronóstico de series, existen varios modelos clásicos para analizar series temporales:
Modelos con variabilidad (varianza) constante
Modelos de media móvil (MA(d)): el modelo queda en función de los ruidos $e_{1},e_{2},...,e_{d}$
Modelos autorregresivos (AR(q)): el modelo queda en función de los ruidos $X_{1},X_{2},...,X_{q}$
Modelos ARMA (ARMA(p,q)): Mezcla de los modelos $MA(d)$ y $AR(q)$
Modelos ARIMA (ARIMA(p,d,q)):: Mezcla de los modelos $MA(d)$ y $AR(q)$ sobre la serie diferenciada $d$ veces.
Modelos SARIMA (SARIMA(p,d,q)x(P,D,Q,S)): Mezcla de los modelos ARIMA(p,d,q) agregando componentes de estacionariedad ($S$).
Dentro de estos modelos, se tiene que uno son un caso particular de otro más general:
$$MA(d),AR(q) \subset ARMA(p,q) \subset ARIMA(p,d,q) \subset SARIMA(p,d,q)x(P,D,Q,S) $$Modelos de volatibilidad
Arch
Garch
Modelos de espacio estado
Se deja como tarea al lector profundizar más en estos conceptos.
Realizar pronóstico con statsmodels¶
El pronóstico lo realizaremos ocupando los modelos disponible en statsmodels, particularmen los modelos $SARIMA(p,d,q)x(P,D,Q,S)$.
Como todo buen proceso de machine learning es necesario separar nuestro conjunto de datos en dos (entrenamiento y testeo). ¿ Cómo se realiza esto con series temporales ?.
El camino correcto para considerar una fecha objetivo (target_date), el cual separé en dos conjuntos, de la siguiente manera:
- y_train: todos los datos hasta la fecha target_date
- y_test: todos los datos después la fecha target_date
target_date = '1958-01-01'
# crear conjunto de entrenamiento y de testeo
mask_ds = y.index < target_date
y_train = y[mask_ds]
y_test = y[~mask_ds]
#plotting the data
y_train['passengers'].plot()
y_test['passengers'].plot()
plt.show()

Una pregunta natural que surgue es: ¿ por qué no se toman datos de manera aleatoria?.
La respuesta es que como se trabaja el la variable tiempo, por lo tanto los datos siguen un orden natural de los sucesos, en cambio, en los problemas de regresión no existe orden en los sucesos, por cada par de punto es de cierta forma independiente uno con otros. Además, si se sacarán puntos de testeo de manera aleatoria, podría romper con la tendencia y estacionariedad original de la serie.
Veamos un ejemplo sensillo de este caso en python:
from statsmodels.tsa.statespace.sarimax import SARIMAX
from metrics_regression import *
# parametros
param = [(1,0,0),(0,0,0,12)]
# modelo
model = SARIMAX(y_train,
order=param[0],
seasonal_order=param[1],
enforce_stationarity=False,
enforce_invertibility=False)
# ajustar modelo
model_fit = model.fit(disp=0)
# fecha de las predicciones
start_index = y_test.index.min()
end_index = y_test.index.max()
preds = model_fit.get_prediction(start=start_index,end=end_index, dynamic=False)
df_temp = pd.DataFrame(
{
'y':y_test['passengers'],
'yhat': preds.predicted_mean
}
)
# resultados del ajuste
df_temp.head()
| y | yhat | |
|---|---|---|
| 1958-01-31 | 340.0 | 336.756041 |
| 1958-02-28 | 318.0 | 337.513783 |
| 1958-03-31 | 362.0 | 338.273230 |
| 1958-04-30 | 348.0 | 339.034386 |
| 1958-05-31 | 363.0 | 339.797254 |
# resultados de las métricas
df_metrics = summary_metrics(df_temp)
df_metrics['model'] = f"SARIMA_{param[0]}X{param[1]}".replace(' ','')
df_metrics
| mae | mse | rmse | mape | maape | wmape | mmape | smape | model | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 81.8529 | 11619.4305 | 107.7935 | 0.1701 | 0.166 | 0.191 | 0.1697 | 0.195 | SARIMA_(1,0,0)X(0,0,0,12) |
# graficamos resultados
preds = df_temp['yhat']
ax = y['1949':].plot(label='observed')
preds.plot(ax=ax, label='Forecast', alpha=.7, figsize=(14, 7))
ax.set_xlabel('Date')
ax.set_ylabel('Passengers')
plt.legend()
plt.show()

Observamos a simple vista que el ajuste no es tan bueno que digamos (analizando las métricas y el gráfico).
Entonces, ¿ qué se puede hacer?. La respuesta es simple ¡ probar varios modelos sarima !.
Ahora, ¿ cómo lo hacemos?. Lo primero es definir una clase llamada SarimaModels que automatice el proceso anterior, y nos quedamos con aquel modelo que minimice alguna de las métricas propuestas, por ejemplo, minimizar las métricas de mae y mape
# creando clase SarimaModels
class SarimaModels:
def __init__(self,params):
self.params = params
@property
def name_model(self):
return f"SARIMA_{self.params[0]}X{self.params[1]}".replace(' ','')
@staticmethod
def test_train_model(y,date):
mask_ds = y.index < date
y_train = y[mask_ds]
y_test = y[~mask_ds]
return y_train, y_test
def fit_model(self,y,date):
y_train, y_test = self.test_train_model(y,date )
model = SARIMAX(y_train,
order=self.params[0],
seasonal_order=self.params[1],
enforce_stationarity=False,
enforce_invertibility=False)
model_fit = model.fit(disp=0)
return model_fit
def df_testig(self,y,date):
y_train, y_test = self.test_train_model(y,date )
model = SARIMAX(y_train,
order=self.params[0],
seasonal_order=self.params[1],
enforce_stationarity=False,
enforce_invertibility=False)
model_fit = model.fit(disp=0)
start_index = y_test.index.min()
end_index = y_test.index.max()
preds = model_fit.get_prediction(start=start_index,end=end_index, dynamic=False)
df_temp = pd.DataFrame(
{
'y':y_test['passengers'],
'yhat': preds.predicted_mean
}
)
return df_temp
def metrics(self,y,date):
df_temp = self.df_testig(y,date)
df_metrics = summary_metrics(df_temp)
df_metrics['model'] = self.name_model
return df_metrics
# definir parametros
import itertools
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
params = list(itertools.product(pdq,seasonal_pdq))
target_date = '1958-01-01'
# iterar para los distintos escenarios
frames = []
for param in params:
try:
sarima_model = SarimaModels(param)
df_metrics = sarima_model.metrics(y,target_date)
frames.append(df_metrics)
except:
pass
C:\Users\franc\AppData\Local\pypoetry\Cache\virtualenvs\docs-rzB-GL7Y-py3.8\lib\site-packages\statsmodels\base\model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
C:\Users\franc\AppData\Local\pypoetry\Cache\virtualenvs\docs-rzB-GL7Y-py3.8\lib\site-packages\statsmodels\base\model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
# juntar resultados de las métricas y comparar
df_metrics_result = pd.concat(frames)
df_metrics_result.sort_values(['mae','mape'])
| mae | mse | rmse | mape | maape | wmape | mmape | smape | model | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 16.4272 | 406.5114 | 20.1621 | 0.0410 | 0.0409 | 0.0383 | 0.0409 | 0.0398 | SARIMA_(0,1,0)X(1,0,0,12) |
| 0 | 17.7173 | 469.8340 | 21.6757 | 0.0420 | 0.0419 | 0.0413 | 0.0419 | 0.0414 | SARIMA_(0,1,1)X(1,1,1,12) |
| 0 | 17.7204 | 480.9764 | 21.9312 | 0.0414 | 0.0414 | 0.0414 | 0.0413 | 0.0411 | SARIMA_(1,1,0)X(1,1,1,12) |
| 0 | 17.8053 | 501.0603 | 22.3844 | 0.0412 | 0.0411 | 0.0416 | 0.0411 | 0.0410 | SARIMA_(1,1,1)X(0,1,0,12) |
| 0 | 17.8056 | 505.4167 | 22.4815 | 0.0411 | 0.0410 | 0.0416 | 0.0410 | 0.0409 | SARIMA_(0,1,0)X(0,1,0,12) |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 0 | 94.9444 | 14674.5556 | 121.1386 | 0.1989 | 0.1933 | 0.2216 | 0.1984 | 0.2320 | SARIMA_(0,1,0)X(0,0,0,12) |
| 0 | 360.7115 | 150709.0664 | 388.2127 | 0.8203 | 0.6687 | 0.8418 | 0.8184 | 1.5247 | SARIMA_(0,0,1)X(0,0,1,12) |
| 0 | 366.5303 | 153175.7993 | 391.3768 | 0.8370 | 0.6811 | 0.8554 | 0.8351 | 1.5623 | SARIMA_(0,0,0)X(0,0,1,12) |
| 0 | 422.9626 | 187068.9748 | 432.5147 | 0.9837 | 0.7745 | 0.9871 | 0.9814 | 1.9589 | SARIMA_(0,0,1)X(0,0,0,12) |
| 0 | 428.5000 | 189730.5556 | 435.5807 | 1.0000 | 0.7854 | 1.0000 | 0.9976 | 2.0000 | SARIMA_(0,0,0)X(0,0,0,12) |
64 rows × 9 columns
En este caso el mejor modelo resulta ser el modelo $SARIMA(0,1,0)X(1,0,0,12)$. Veamos gráficamente que tal el ajuste de este modelo.
# ajustar mejor modelo
param = [(0,1,0),(1,0,0,12)]
sarima_model = SarimaModels(param)
model_fit = sarima_model.fit_model(y,target_date)
best_model = sarima_model.df_testig(y,target_date)
best_model.head()
| y | yhat | |
|---|---|---|
| 1958-01-31 | 340.0 | 345.765806 |
| 1958-02-28 | 318.0 | 330.574552 |
| 1958-03-31 | 362.0 | 390.254476 |
| 1958-04-30 | 348.0 | 381.573760 |
| 1958-05-31 | 363.0 | 389.169386 |
# graficar mejor modelo
preds = best_model['yhat']
ax = y['1949':].plot(label='observed')
preds.plot(ax=ax, label='Forecast', alpha=.7, figsize=(14, 7))
ax.set_xlabel('Date')
ax.set_ylabel('Passengers')
plt.legend()
plt.show()

Para este caso, el mejor modelo encontrado se ajusta bastante bien a los datos.
Finalmente, vemos algunos resultados del error asosciado al modelo. Para esto ocupamos la herramienta plot_diagnostics, el cual nos arroja cuatro gráficos analizando el error de diferentes manera.
# resultados del error
model_fit.plot_diagnostics(figsize=(16, 8))
plt.show()

- gráfico 01 (standarized residual): Este gráfico nos muestra el error estandarizado en el tiempo. En este caso se observa que esta nueva serie de tiempo corresponde a una serie estacionaria que oscila entorno al cero, es decir, un ruido blanco.
- gráfico 02 (histogram plus estimated density): Este gráfico nos muestra el histograma del error. En este caso, el histograma es muy similar al histograma de una variable $\mathcal{N}(0,1)$ (ruido blanco).
- gráfico 03 (normal QQ): el gráfico Q-Q ("Q" viene de cuantil) es un método gráfico para el diagnóstico de diferencias entre la distribución de probabilidad de una población de la que se ha extraído una muestra aleatoria y una distribución usada para la comparación. En este caso se comparar la distribución del error versus una distribución normal. Cuando mejor es el ajuste lineal sobre los puntos, más parecida es la distribución entre la muestra obtenida y la distribución de prueba (distribución normal).
- gráfico 04 (correlogram): Este gráfico nos muestra el gráfico de autocorrelación entre las variables del error, se observa que no hay correlación entre ninguna de las variables, por lo que se puedan dar indicios de independencia entre las variables.
En conclusión, el error asociado al modelo en estudio corresponde a un ruido blanco.
Prophet¶
Prophet es un procedimiento para pronosticar datos de series temporales basado en un modelo aditivo en el que las tendencias no lineales se ajustan a la estacionalidad anual, semanal y diaria, además de los efectos de las vacaciones. Funciona mejor con series temporales que tienen fuertes efectos estacionales y varias temporadas de datos históricos. Prophet es resistente a los datos faltantes y los cambios en la tendencia, y por lo general maneja bien los valores atípicos.
Prophet es un software de código abierto lanzado por el equipo Core Data Science de Facebook. Está disponible para descargar en CRAN y PyPI.
Nota: Para entender mejor este algoritmo, puede leer el siguiente paper.
from prophet import Prophet
# rename
y_train_prophet = y_train.reset_index()
y_train_prophet.columns = ["ds","y"]
y_test_prophet = y_test.reset_index()
y_test_prophet.columns = ["ds","y"]
# model
m = Prophet()
m.fit(y_train_prophet)
16:57:37 - cmdstanpy - INFO - Chain [1] start processing 16:57:37 - cmdstanpy - INFO - Chain [1] done processing
<prophet.forecaster.Prophet at 0x1ffaa49c2b0>
# forecast
future = m.make_future_dataframe(periods=365*4)
forecast = m.predict(future)[['ds', 'yhat']]
forecast.tail()
| ds | yhat | |
|---|---|---|
| 1563 | 1961-12-26 | 537.468542 |
| 1564 | 1961-12-27 | 536.680708 |
| 1565 | 1961-12-28 | 534.858775 |
| 1566 | 1961-12-29 | 532.014491 |
| 1567 | 1961-12-30 | 528.188389 |
# metrics
result = y_test_prophet.merge(forecast,on = 'ds',how='inner')
summary_metrics(result)
| mae | mse | rmse | mape | maape | wmape | mmape | smape | |
|---|---|---|---|---|---|---|---|---|
| 0 | 39.72 | 1998.9305 | 44.7094 | 0.0979 | 0.0973 | 0.0927 | 0.0977 | 0.0936 |
preds = result[['ds','yhat']].set_index("ds")
ax = y['1949':].plot(label='observed')
preds.plot(ax=ax, label='Forecast', alpha=.7, figsize=(14, 7))
ax.set_xlabel('Date')
ax.set_ylabel('Passengers')
plt.legend()
plt.show()

Conclusión¶
Este fue una introducción amigable a los conceptos claves de series temporales, a medida que más se profundice en la teoría, mejor serán las técnicas empleadas sobre la serie temporal en fin de obtener el mejor pronóstico posible.
En esta sección nos limitamos a algunos modelos y algunos criterios de verificación de estacionariedad. En la literatura existen muchas más, pero con los mostrados de momento y un poco de expertice en el tema, se pueden abordar casi todos los problemas de series temporales.