![]()
Pandas II¶
Groupby¶
Groupby es un concepto bastante simple. Podemos crear una agrupación de categorías y aplicar una función a las categorías.
El proceso de groupby se puede resumiren los siguientes pasos:
- División: es un proceso en el que dividimos los datos en grupos aplicando algunas condiciones en los conjuntos de datos.
- Aplicación: es un proceso en el que aplicamos una función a cada grupo de forma independiente
- Combinación: es un proceso en el que combinamos diferentes conjuntos de datos después de aplicar groupby y resultados en una estructura de datos

Después de dividir los datos en un grupo, aplicamos una función a cada grupo para realizar algunas operaciones que son:
- Agregación: es un proceso en el que calculamos una estadística resumida (o estadística) sobre cada grupo. Por ejemplo, Calcular sumas de grupo o medios
- Transformación: es un proceso en el que realizamos algunos cálculos específicos del grupo y devolvemos un índice similar. Por ejemplo, llenar NA dentro de grupos con un valor derivado de cada grupo
- Filtración: es un proceso en el cual descartamos algunos grupos, de acuerdo con un cálculo grupal que evalúa Verdadero o Falso. Por ejemplo, Filtrar datos en función de la suma o media grupal
import pandas as pd
import numpy as np
# cargar datos
path = 'https://raw.githubusercontent.com/fralfaro/MAT281_2024/main/docs/lectures/data_manipulation/data/player_info.csv'
df = pd.read_csv(path, sep="," ).dropna()
df['Decade'] = df['year_start'].apply(lambda x: '2000' if x>=2000 else '1900')
df.head()
| name | year_start | year_end | position | height | weight | birth_date | college | Decade | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University | 1900 |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles | 1900 |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University | 1900 |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University | 1900 |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California | 1900 |
Agrupar por una columna¶
# Agrupar por 'Decade' y calcular la suma de la columna 'Open' en cada grupo
agrupado = df.groupby('position')['weight'].mean()
agrupado
position C 242.219212 C-F 228.256158 F 217.985857 F-C 222.871866 F-G 202.604878 G 186.828115 G-F 197.017857 Name: weight, dtype: float64
Agrupar por varias columnas¶
# Agrupar por 'Year','Month' y calcular la suma de la columna 'Open' en cada grupo
agrupado = df.groupby(['Decade','position'])['weight'].mean()
agrupado
Decade position
1900 C 237.453642
C-F 224.871345
F 212.582933
F-C 217.908475
F-G 200.594444
G 182.689150
G-F 192.789062
2000 C 256.057692
C-F 246.343750
F 230.135135
F-C 245.750000
F-G 217.080000
G 195.686192
G-F 210.550000
Name: weight, dtype: float64
Aplicar múltiples funciones¶
# Agrupar por 'Year','Month' y calcular la suma,promedio de la columna 'Open' en cada grupo
agrupado = df.groupby(['Decade','position']).agg({'weight': ['sum', 'mean']})
agrupado
| weight | |||
|---|---|---|---|
| sum | mean | ||
| Decade | position | ||
| 1900 | C | 71711.0 | 237.453642 |
| C-F | 38453.0 | 224.871345 | |
| F | 176869.0 | 212.582933 | |
| F-C | 64283.0 | 217.908475 | |
| F-G | 36107.0 | 200.594444 | |
| G | 186891.0 | 182.689150 | |
| G-F | 49354.0 | 192.789062 | |
| 2000 | C | 26630.0 | 256.057692 |
| C-F | 7883.0 | 246.343750 | |
| F | 85150.0 | 230.135135 | |
| F-C | 15728.0 | 245.750000 | |
| F-G | 5427.0 | 217.080000 | |
| G | 93538.0 | 195.686192 | |
| G-F | 16844.0 | 210.550000 | |
Groupby Apply¶
# Definimos una función que calcula el promedio armónico
def promedio_armónico(datos):
n = len(datos)
suma_recíprocos = sum(1 / x for x in datos)
promedio_armónico = n / suma_recíprocos
return promedio_armónico
# Aplicamos la función
df.groupby(['Decade', 'position'])['weight'].apply(promedio_armónico)
Decade position
1900 C 235.811208
C-F 223.766067
F 211.205181
F-C 216.785001
F-G 199.669744
G 181.746894
G-F 191.847770
2000 C 254.688414
C-F 245.646696
F 228.989635
F-C 244.951294
F-G 216.310153
G 194.579990
G-F 209.851256
Name: weight, dtype: float64
Groupby Transform¶
En pandas, el método transform() permite aplicar una función de transformación a cada grupo de un objeto groupby. La función de transformación se aplica a cada grupo y el resultado se asigna de vuelta a las filas correspondientes en el DataFrame original.
df['mean_weight'] = df.groupby(['Decade','position'])['weight'].transform('mean')
df.head()
| name | year_start | year_end | position | height | weight | birth_date | college | Decade | mean_weight | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University | 1900 | 224.871345 |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles | 1900 | 237.453642 |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University | 1900 | 182.689150 |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University | 1900 | 212.582933 |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California | 1900 | 212.582933 |
Concat¶
La función concat() realiza todo el trabajo pesado de realizar operaciones de concatenación a lo largo de un eje mientras realiza la lógica de conjunto opcional (unión o intersección) de los índices (si los hay) en los otros ejes. Tenga en cuenta que digo "si hay alguno" porque solo hay un único eje posible de concatenación para Series.
# cargar datos
path = 'data/player_info.csv'
df = pd.read_csv(path, sep="," ).dropna()
df.head()
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California |
# crear datos
df_concat1 = df.loc[lambda x: x['year_start']<2000]
df_concat1.head()
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California |
# crear datos
df_concat2 = df.loc[lambda x: x['year_start']>=2000]
df_concat2.head()
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 11 | Alex Acker | 2006 | 2009 | G | 6-5 | 185.0 | January 21, 1983 | Pepperdine University |
| 15 | Quincy Acy | 2013 | 2018 | F | 6-7 | 240.0 | October 6, 1990 | Baylor University |
| 19 | Hassan Adams | 2007 | 2009 | G | 6-4 | 220.0 | June 20, 1984 | University of Arizona |
| 20 | Jordan Adams | 2015 | 2016 | G | 6-5 | 209.0 | July 8, 1994 | University of California, Los Angeles |
| 22 | Steven Adams | 2014 | 2018 | C | 7-0 | 255.0 | July 20, 1993 | University of Pittsburgh |
Concatenar varias tablas con las mismas columnas¶
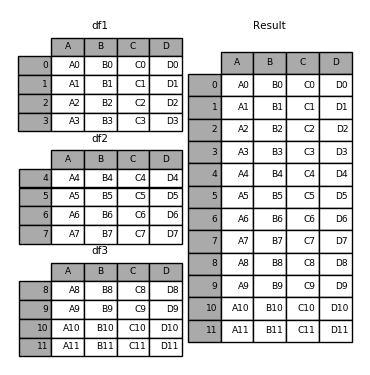
# concatenar mismas columnas
result = pd.concat([df_concat1,df_concat2])
# mostrar resultados
result
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4533 | Cody Zeller | 2014 | 2018 | C-F | 7-0 | 240.0 | October 5, 1992 | Indiana University |
| 4537 | Luke Zeller | 2013 | 2013 | C | 6-11 | 245.0 | April 7, 1987 | University of Notre Dame |
| 4538 | Tyler Zeller | 2013 | 2018 | F-C | 7-0 | 253.0 | January 17, 1990 | University of North Carolina |
| 4543 | Derrick Zimmerman | 2006 | 2006 | G | 6-3 | 195.0 | December 2, 1981 | Mississippi State University |
| 4544 | Stephen Zimmerman | 2017 | 2017 | C | 7-0 | 240.0 | September 9, 1996 | University of Nevada, Las Vegas |
4212 rows × 8 columns
Concatenar varias tablas distintas columnas¶

# cambiar nombre
df_concat2 = df_concat2.rename(columns = {'birth_date':'birth'})
# concatenar mismas columnas
result = pd.concat([df_concat2,df_concat1])
# mostrar resultados
result
| name | year_start | year_end | position | height | weight | birth | college | birth_date | |
|---|---|---|---|---|---|---|---|---|---|
| 11 | Alex Acker | 2006 | 2009 | G | 6-5 | 185.0 | January 21, 1983 | Pepperdine University | NaN |
| 15 | Quincy Acy | 2013 | 2018 | F | 6-7 | 240.0 | October 6, 1990 | Baylor University | NaN |
| 19 | Hassan Adams | 2007 | 2009 | G | 6-4 | 220.0 | June 20, 1984 | University of Arizona | NaN |
| 20 | Jordan Adams | 2015 | 2016 | G | 6-5 | 209.0 | July 8, 1994 | University of California, Los Angeles | NaN |
| 22 | Steven Adams | 2014 | 2018 | C | 7-0 | 255.0 | July 20, 1993 | University of Pittsburgh | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4540 | Phil Zevenbergen | 1988 | 1988 | C | 6-10 | 230.0 | NaN | University of Washington | April 13, 1964 |
| 4542 | George Zidek | 1996 | 1998 | C | 7-0 | 250.0 | NaN | University of California, Los Angeles | August 2, 1973 |
| 4547 | Jim Zoet | 1983 | 1983 | C | 7-1 | 240.0 | NaN | Kent State University | December 20, 1953 |
| 4548 | Bill Zopf | 1971 | 1971 | G | 6-1 | 170.0 | NaN | Duquesne University | June 7, 1948 |
| 4550 | Matt Zunic | 1949 | 1949 | G-F | 6-3 | 195.0 | NaN | George Washington University | December 19, 1919 |
4212 rows × 9 columns
Merge¶
La función merge() se usa para combinar dos (o más) tablas sobre valores de columnas comunes (keys).
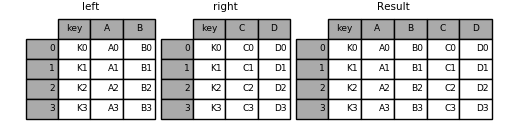
# cargar datos
path = 'data/player_info.csv'
df = pd.read_csv(path, sep="," ).dropna()
df.head()
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California |
Por un columna
# crear datos
cols_merge1 = ['name', 'year_start', 'year_end', 'position']
df_merge1 = df[cols_merge1]
df_merge1.head()
| name | year_start | year_end | position | |
|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F |
# crear datos
cols_merge2 = ['name', 'height', 'weight','birth_date', 'college']
df_merge2 = df[cols_merge2]
df_merge2.head()
| name | height | weight | birth_date | college | |
|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 3 | Kareem Abdul-Jabbar | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 4 | Mahmoud Abdul-Rauf | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 5 | Tariq Abdul-Wahad | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 6 | Shareef Abdur-Rahim | 6-9 | 225.0 | December 11, 1976 | University of California |
# merge por una columna
result = pd.merge(df_merge1, df_merge2, on='name')
result.head()
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 0 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 1 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 2 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 3 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 4 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California |
Por Varias columnas
# crear datos
cols_merge1 = ['name', 'year_start', 'year_end', 'position']
df_merge1 = df[cols_merge1]
df_merge1.head()
| name | year_start | year_end | position | |
|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F |
# crear datos
cols_merge2 = ['name', 'year_start', 'year_end', 'height', 'weight','birth_date', 'college']
df_merge2 = df[cols_merge2]
df_merge2.head()
| name | year_start | year_end | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | 6-9 | 225.0 | December 11, 1976 | University of California |
# merge varias columnas
result = pd.merge(df_merge1, df_merge2, on=['name', 'year_start', 'year_end'])
result.head()
| name | year_start | year_end | position | height | weight | birth_date | college | |
|---|---|---|---|---|---|---|---|---|
| 0 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University |
| 1 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles |
| 2 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University |
| 3 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University |
| 4 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California |
Tipos de merge¶
La opción how especificica el tipo de cruce que se realizará.
- left: usa las llaves solo de la tabla izquierda
- right: usa las llaves solo de la tabla derecha
- outer: usa las llaves de la unión de ambas tablas.
- inner: usa las llaves de la intersección de ambas tablas.





# tipos de merge
cols = ['name', 'year_start', 'year_end']
merge_left = pd.merge(df_merge1, df_merge2, on=cols, how= 'left')
merge_rigth = pd.merge(df_merge1, df_merge2, on=cols, how= 'right')
merge_inner = pd.merge(df_merge1, df_merge2, on=cols, how= 'inner')
merge_outer = pd.merge(df_merge1, df_merge2, on=cols, how= 'outer')
Problemas de llaves duplicadas¶
Cuando se quiere realizar el cruce de dos tablas, pero an ambas tablas existe una columna (key) con el mismo nombre, para diferenciar la información entre la columna de una tabla y otra, pandas devulve el nombre de la columna con un guión bajo x (key_x) y otra con un guión bajo y (key_y)
df.columns
Index(['name', 'year_start', 'year_end', 'position', 'height', 'weight',
'birth_date', 'college'],
dtype='object')
# crear datos
cols_merge1 = ['name', 'year_start', 'year_end', 'position' ]
df_merge1 = df[cols_merge1]
df_merge1.head()
| name | year_start | year_end | position | |
|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F |
# crear datos
cols_merge2 = ['name', 'year_start', 'year_end', 'height' ]
df_merge2 = df[cols_merge2]
df_merge2.head()
| name | year_start | year_end | height | |
|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | 6-9 |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | 7-2 |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | 6-1 |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | 6-6 |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | 6-9 |
# merge llaves duplicadas
result = pd.merge(df_merge1, df_merge2, on=['name', 'year_start'])
result.head()
| name | year_start | year_end_x | position | year_end_y | height | |
|---|---|---|---|---|---|---|
| 0 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 1978 | 6-9 |
| 1 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 1989 | 7-2 |
| 2 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 2001 | 6-1 |
| 3 | Tariq Abdul-Wahad | 1998 | 2003 | F | 2003 | 6-6 |
| 4 | Shareef Abdur-Rahim | 1997 | 2008 | F | 2008 | 6-9 |
Tipos de Formatos¶

Dentro del mundo de los dataframe (o datos tabulares) existen dos formas de presentar la naturaleza de los datos: formato wide y formato long.
Ejemplo, el siguiente conjunto de datos representa estadísticas de rendimiento para cuatro equipos (A, B, C y D) en un cierto contexto deportivo. Cada fila corresponde a un equipo y muestra tres medidas diferentes de rendimiento.
| Team | Points | Assists | Rebounds |
|---|---|---|---|
| A | 88 | 12 | 22 |
| B | 91 | 17 | 28 |
| C | 99 | 24 | 30 |
| D | 94 | 28 | 31 |
La tabla así presentada se encuentra en wide format, es decir, donde los valores se extienden a través de las columnas.
Sería posible representar el mismo contenido anterior en long format, es decir, donde los mismos valores se indicaran a través de las filas:
| Team | Variable | Value |
|---|---|---|
| A | Points | 88 |
| A | Assists | 12 |
| A | Rebounds | 22 |
| B | Points | 91 |
| B | Assists | 17 |
| B | Rebounds | 28 |
| C | Points | 99 |
| C | Assists | 24 |
| C | Rebounds | 30 |
| D | Points | 94 |
| D | Assists | 28 |
| D | Rebounds | 31 |
Formato long a wide¶
El pivoteo de una tabla corresponde al paso de una tabla desde el formato long al formato wide. Típicamente esto se realiza para poder comparar los valores que se obtienen para algún registro en particular, o para utilizar algunas herramientas de visualización básica que requieren dicho formato.
En Pandas se utiliza los comandos pivot y pivot_table. Formato long a wide
El pivoteo de una tabla corresponde al paso de una tabla desde el formato long al formato wide. Típicamente esto se realiza para poder comparar los valores que se obtienen para algún registro en particular, o para utilizar algunas herramientas de visualización básica que requieren dicho formato.
En Pandas se utiliza los comandos pivot y pivot_table.
# cargar datos
path = 'data/player_info.csv'
df = pd.read_csv(path, sep="," ).dropna().drop_duplicates()
df['Decade'] = df['year_start'].apply(lambda x: '2000' if x>=2000 else '1900')
df.head()
| name | year_start | year_end | position | height | weight | birth_date | college | Decade | |
|---|---|---|---|---|---|---|---|---|---|
| 2 | Zaid Abdul-Aziz | 1969 | 1978 | C-F | 6-9 | 235.0 | April 7, 1946 | Iowa State University | 1900 |
| 3 | Kareem Abdul-Jabbar | 1970 | 1989 | C | 7-2 | 225.0 | April 16, 1947 | University of California, Los Angeles | 1900 |
| 4 | Mahmoud Abdul-Rauf | 1991 | 2001 | G | 6-1 | 162.0 | March 9, 1969 | Louisiana State University | 1900 |
| 5 | Tariq Abdul-Wahad | 1998 | 2003 | F | 6-6 | 223.0 | November 3, 1974 | San Jose State University | 1900 |
| 6 | Shareef Abdur-Rahim | 1997 | 2008 | F | 6-9 | 225.0 | December 11, 1976 | University of California | 1900 |
# pivot: simple
agrupado = df.groupby(['Decade','position'])['weight'].mean().reset_index()
pivot_df = agrupado.pivot(index='Decade', columns='position', values='weight')
pivot_df.head(10)
| position | C | C-F | F | F-C | F-G | G | G-F |
|---|---|---|---|---|---|---|---|
| Decade | |||||||
| 1900 | 237.453642 | 224.871345 | 212.582933 | 217.908475 | 200.594444 | 182.689150 | 192.789062 |
| 2000 | 256.057692 | 246.343750 | 230.135135 | 245.750000 | 217.080000 | 195.686192 | 210.550000 |
# pivot: multiple
agrupado = df.groupby(['Decade','position','height'])['weight'].mean().fillna(0).astype(int).reset_index()
pivot_df = agrupado.pivot(index=['Decade','height'], columns='position', values='weight').fillna(0)
pivot_df.head(10)
| position | C | C-F | F | F-C | F-G | G | G-F | |
|---|---|---|---|---|---|---|---|---|
| Decade | height | |||||||
| 1900 | 5-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 167.0 | 163.0 |
| 5-11 | 0.0 | 0.0 | 0.0 | 0.0 | 175.0 | 171.0 | 171.0 | |
| 5-3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 136.0 | 0.0 | |
| 5-5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 135.0 | 0.0 | |
| 5-6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 149.0 | 0.0 | |
| 5-7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 150.0 | 0.0 | |
| 5-8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 165.0 | 0.0 | |
| 5-9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 159.0 | 0.0 | |
| 6-0 | 0.0 | 0.0 | 191.0 | 0.0 | 180.0 | 173.0 | 177.0 | |
| 6-1 | 0.0 | 0.0 | 180.0 | 0.0 | 190.0 | 177.0 | 182.0 |
# pivot_table: simple
pivot_df = df.pivot_table(index='Decade', columns='position', values='weight', aggfunc='mean')
pivot_df.head(10)
| position | C | C-F | F | F-C | F-G | G | G-F |
|---|---|---|---|---|---|---|---|
| Decade | |||||||
| 1900 | 237.453642 | 224.871345 | 212.582933 | 217.908475 | 200.594444 | 182.689150 | 192.789062 |
| 2000 | 256.057692 | 246.343750 | 230.135135 | 245.750000 | 217.080000 | 195.686192 | 210.550000 |
# pivot_table: multiple
pivot_df = df.pivot_table(index=['Decade','height'], columns='position', values='weight', aggfunc='mean').fillna(0)
pivot_df.head(10)
| position | C | C-F | F | F-C | F-G | G | G-F | |
|---|---|---|---|---|---|---|---|---|
| Decade | height | |||||||
| 1900 | 5-10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 167.914286 | 163.333333 |
| 5-11 | 0.0 | 0.0 | 0.0 | 0.0 | 175.0 | 171.666667 | 171.666667 | |
| 5-3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 136.000000 | 0.000000 | |
| 5-5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 135.000000 | 0.000000 | |
| 5-6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 149.000000 | 0.000000 | |
| 5-7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 150.833333 | 0.000000 | |
| 5-8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 165.000000 | 0.000000 | |
| 5-9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 159.363636 | 0.000000 | |
| 6-0 | 0.0 | 0.0 | 191.5 | 0.0 | 180.0 | 173.722772 | 177.500000 | |
| 6-1 | 0.0 | 0.0 | 180.0 | 0.0 | 190.0 | 177.728916 | 182.333333 |
Formato wide a long¶
El despivotear una tabla corresponde al paso de una tabla desde el formato wide al formato long.
Se reconocen dos situaciones:
- El valor indicado para la columna es único, y sólo se requiere definir correctamente las columnas.
- El valor indicado por la columna no es único, y se requiere una iteración más profunda.
Para despivotear un dataframe en Pandas, utilizaremos el comando melt.
cols_index = ['name','year_start','year_end']
pivot_df = df.pivot_table(index=cols_index, columns='position', values='weight', aggfunc='mean').fillna(0).reset_index()
pivot_df.head()
| position | name | year_start | year_end | C | C-F | F | F-C | F-G | G | G-F |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A.C. Green | 1986 | 2001 | 0.0 | 0.0 | 0.0 | 220.0 | 0.0 | 0.0 | 0.0 |
| 1 | A.J. Bramlett | 2000 | 2000 | 227.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | A.J. English | 1991 | 1992 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 175.0 | 0.0 |
| 3 | A.J. Guyton | 2001 | 2003 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 180.0 | 0.0 |
| 4 | A.J. Hammons | 2017 | 2017 | 260.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
# aplicar comando melt
df_melt = pd.melt(
df,
id_vars=cols_index,
var_name='Type',
value_name='Value'
)
df_melt = df_melt.drop('Type',axis=1).rename(columns={'Value':'position'})
df_melt.head()
| name | year_start | year_end | position | |
|---|---|---|---|---|
| 0 | Zaid Abdul-Aziz | 1969 | 1978 | C-F |
| 1 | Kareem Abdul-Jabbar | 1970 | 1989 | C |
| 2 | Mahmoud Abdul-Rauf | 1991 | 2001 | G |
| 3 | Tariq Abdul-Wahad | 1998 | 2003 | F |
| 4 | Shareef Abdur-Rahim | 1997 | 2008 | F |