![]()
Tipos de Gráficos¶
Introducción¶
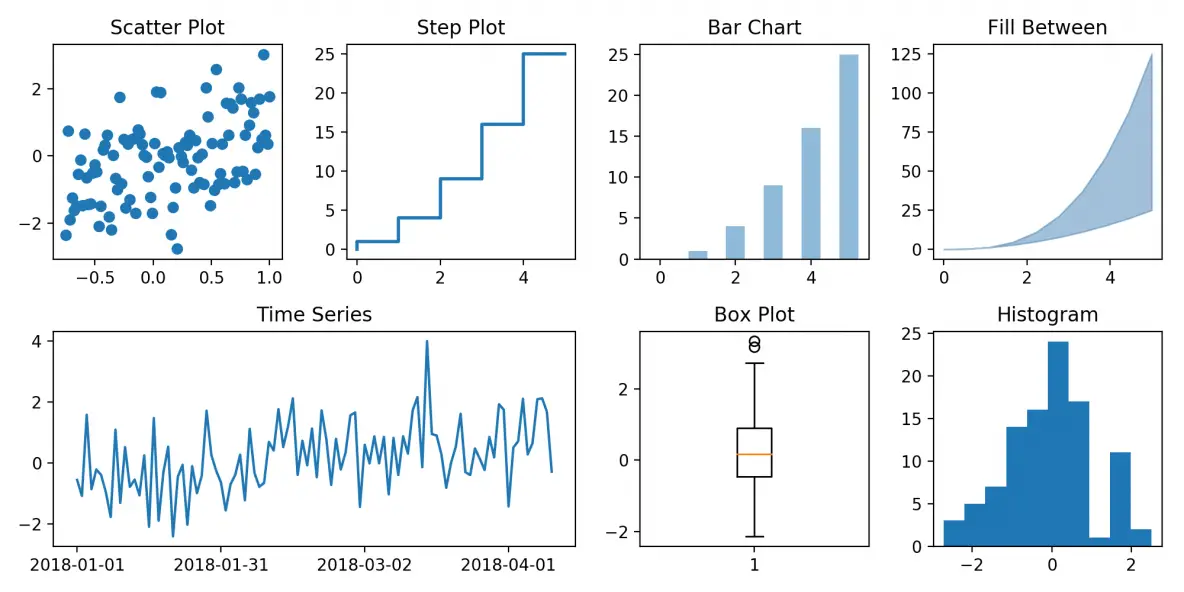
En estadística, un gráfico es una representación visual de datos que permite resumir, analizar y comunicar información de manera efectiva. Los gráficos se utilizan ampliamente en estadística para mostrar patrones, tendencias, distribuciones y relaciones entre variables.
Algunos de los tipos de gráficos más comunes utilizados en estadística incluyen:
Anatomía de un Gráfico¶
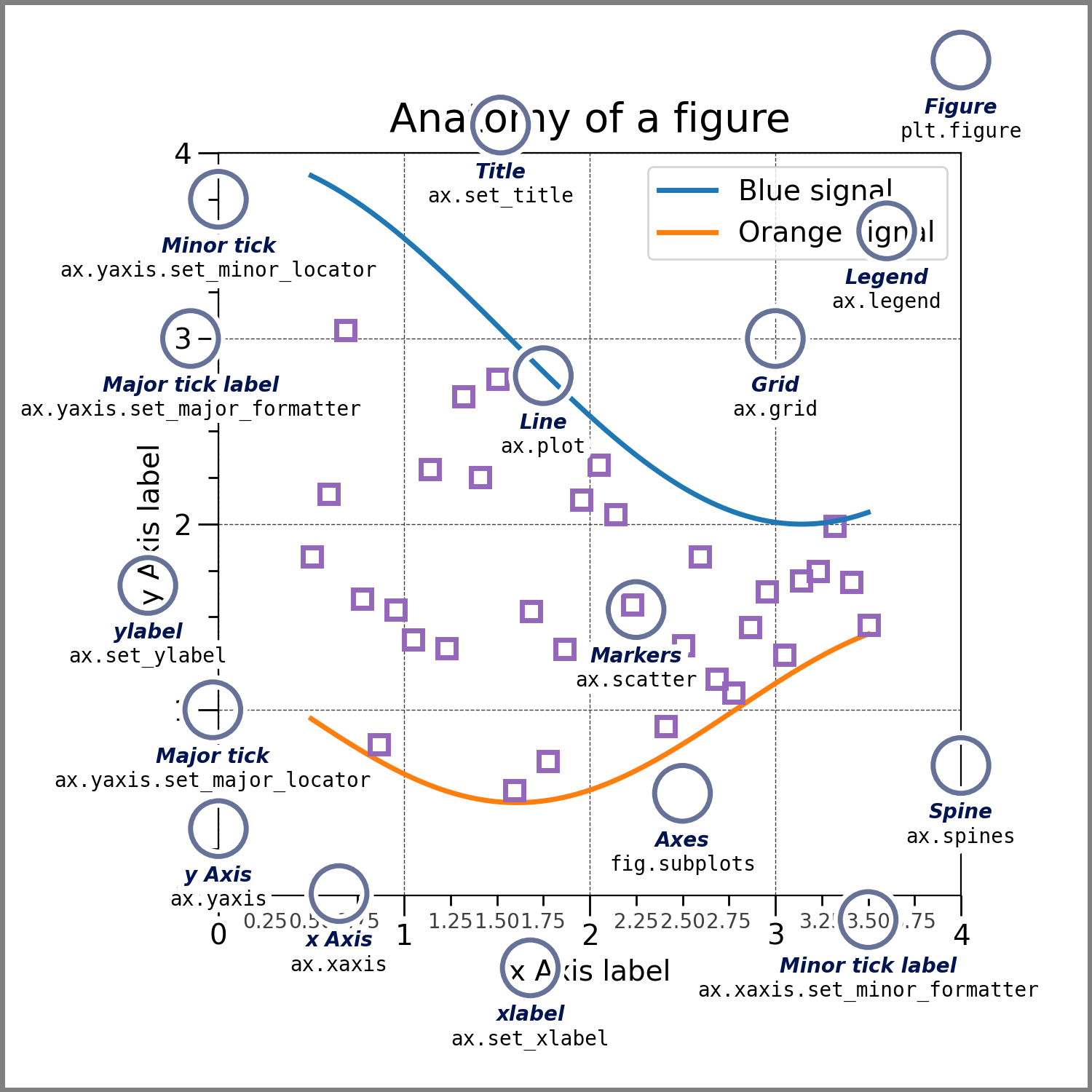
La anatomía de un gráfico se refiere a las diferentes partes o componentes que lo componen. En el contexto de la visualización de datos, la anatomía de un gráfico incluiría elementos como:
Ejes (Axes): Los ejes son los marcos rectangulares donde se representan los datos. Pueden tener etiquetas en los ejes x (horizontal) y y (vertical).
Título (Title): Es el texto que describe la información que se muestra en el gráfico.
Etiquetas de los ejes (Axis Labels): Son textos que describen qué se está representando en cada eje. Por ejemplo, en un gráfico de dispersión, se puede etiquetar el eje x como "Variable independiente" y el eje y como "Variable dependiente".
Leyenda (Legend): Es una caja o área que explica el significado de los diferentes elementos en el gráfico, como líneas o colores, especialmente cuando hay múltiples conjuntos de datos representados.
Puntos de datos (Data Points): Son los puntos individuales que representan observaciones o valores en el gráfico.
Líneas (Lines): Se utilizan para conectar puntos de datos y representar relaciones entre ellos, como en gráficos de líneas o de series temporales.
Barras (Bars): Se utilizan en gráficos de barras para representar la magnitud de diferentes categorías o variables.
Cuadrícula (Grid): Las líneas de cuadrícula ayudan a visualizar y comparar los valores en el gráfico.
Fondo (Background): El área que rodea el gráfico, generalmente blanco o de otro color sólido, que proporciona contraste con los elementos del gráfico.
Gráfico de Línea¶
Un gráfico de líneas es un tipo de gráfico que utiliza una o varias líneas para mostrar la relación entre dos o más variables. Es comúnmente utilizado en estadística para representar datos numéricos a lo largo de un eje horizontal y vertical, y para observar tendencias o cambios en los datos a lo largo del tiempo o de una escala continua.
En un gráfico de líneas, cada punto representa el valor de una variable en un momento determinado. Estos puntos se unen mediante una línea, lo que permite visualizar la tendencia general de los datos. Además, se pueden añadir múltiples líneas en un mismo gráfico para comparar diferentes series de datos y observar las diferencias en su comportamiento a lo largo del tiempo o de una escala continua.
import matplotlib.pyplot as plt
import numpy as np
# Definir los datos para los ejes x e y
x = [1, 2, 3, 4, 5]
y = [10, 12, 15, 20, 22]
# Crear gráfico
plt.plot(x, y)
plt.xlabel('Eje x')
plt.ylabel('Eje y')
plt.title('Gráfico de líneas')
# Mostrar el gráfico
plt.show()

Gráfico de Dispersión¶
Un gráfico de dispersión es un tipo de gráfico que muestra la relación entre dos variables numéricas. En este tipo de gráfico, cada punto en el eje horizontal representa un valor de la primera variable, y cada punto en el eje vertical representa un valor de la segunda variable. Los puntos se distribuyen en el gráfico según los valores que tienen en ambas variables.
Los gráfico de dispersión son útiles para observar si existe una relación entre dos variables y cómo se relacionan entre sí. Si los puntos están agrupados de manera que forman una línea o una curva, esto sugiere una relación entre las dos variables. Si los puntos están dispersos aleatoriamente, esto sugiere que no hay una relación clara entre las dos variables.
# Definir los datos para los ejes x e y
x = [1, 2, 3, 4, 5]
y = [10, 12, 15, 20, 22]
# Crear gráfico
plt.scatter(x, y)
plt.xlabel('Eje x')
plt.ylabel('Eje y')
plt.title('Diagrama de dispersión')
# Mostrar el gráfico
plt.show()

Gráfico de Barras¶
Un gráfico de barras es un tipo de gráfico utilizado para representar datos numéricos mediante barras rectangulares, donde la longitud de cada barra representa la magnitud de la cantidad correspondiente. Este tipo de gráfico es útil para comparar datos entre diferentes categorías o grupos.
En un gráfico de barras, cada barra representa una categoría o grupo, y la altura o longitud de la barra representa el valor numérico de la cantidad que se está midiendo. Las barras pueden ser horizontales o verticales, dependiendo de la preferencia del usuario o de la forma en que se ajuste mejor a los datos.
# Definir los datos para los ejes x e y
x = ['A', 'B', 'C', 'D', 'E']
y = [100, 200, 150, 300, 250]
# Crear gráfico
plt.bar(x, y)
plt.xlabel('Productos')
plt.ylabel('Cantidad vendida')
plt.title('Ventas por producto')
# Mostrar el gráfico
plt.show()

Gráfico: Histograma¶
Un histograma es un tipo de gráfico utilizado en estadística para representar la distribución de frecuencia de un conjunto de datos numéricos. En un histograma, los datos se dividen en rangos o intervalos (también conocidos como "bins" o "clases"), y se cuenta cuántas veces aparece un valor dentro de cada rango. Estas frecuencias se representan mediante barras rectangulares, donde la altura de cada barra representa la frecuencia de los valores en ese rango.
Los histogramas son útiles para visualizar la distribución de frecuencias de un conjunto de datos, lo que permite identificar patrones, tendencias y valores atípicos. También se pueden utilizar para comparar la distribución de diferentes conjuntos de datos.
# Crear un conjunto de datos aleatorios con una distribución normal
data = np.random.randn(10000)
# Crear el histograma con 20 bins y color verde
plt.hist(data, bins=20,edgecolor='black')
# Agregar etiquetas y título
plt.xlabel('Valores')
plt.ylabel('Frecuencia')
plt.title('Histograma de valores aleatorios')
# Mostrar el histograma
plt.show()

Gráfico: Heatmap¶
Un heatmap (mapa de calor en español) es un tipo de gráfico que utiliza colores para representar la magnitud de una variable en una matriz o tabla de datos. En un heatmap, cada celda de la matriz se colorea en función de su valor, de tal manera que los valores más altos se representan con colores más intensos y los valores más bajos con colores más suaves.
Los heatmaps son especialmente útiles para visualizar grandes cantidades de datos en forma de matrices, ya que permiten identificar patrones, tendencias y valores atípicos de manera más eficiente que si se utilizaran tablas numéricas. Por ejemplo, se pueden utilizar para visualizar patrones de tráfico en una red de computadoras, o para mostrar la correlación entre distintas variables en un conjunto de datos.
# Crear una matriz aleatoria de 5x5
data = np.random.rand(5, 5)
# Crear el heatmap con la función imshow
plt.imshow(data, cmap='Blues')
# Agregar etiquetas y título
plt.colorbar()
plt.xticks(range(5), ['A', 'B', 'C', 'D', 'E'])
plt.yticks(range(5), ['1', '2', '3', '4', '5'])
plt.xlabel('Columnas')
plt.ylabel('Filas')
plt.title('Heatmap de una matriz aleatoria')
# Mostrar el heatmap
plt.show()

Gráfico: Boxplot¶
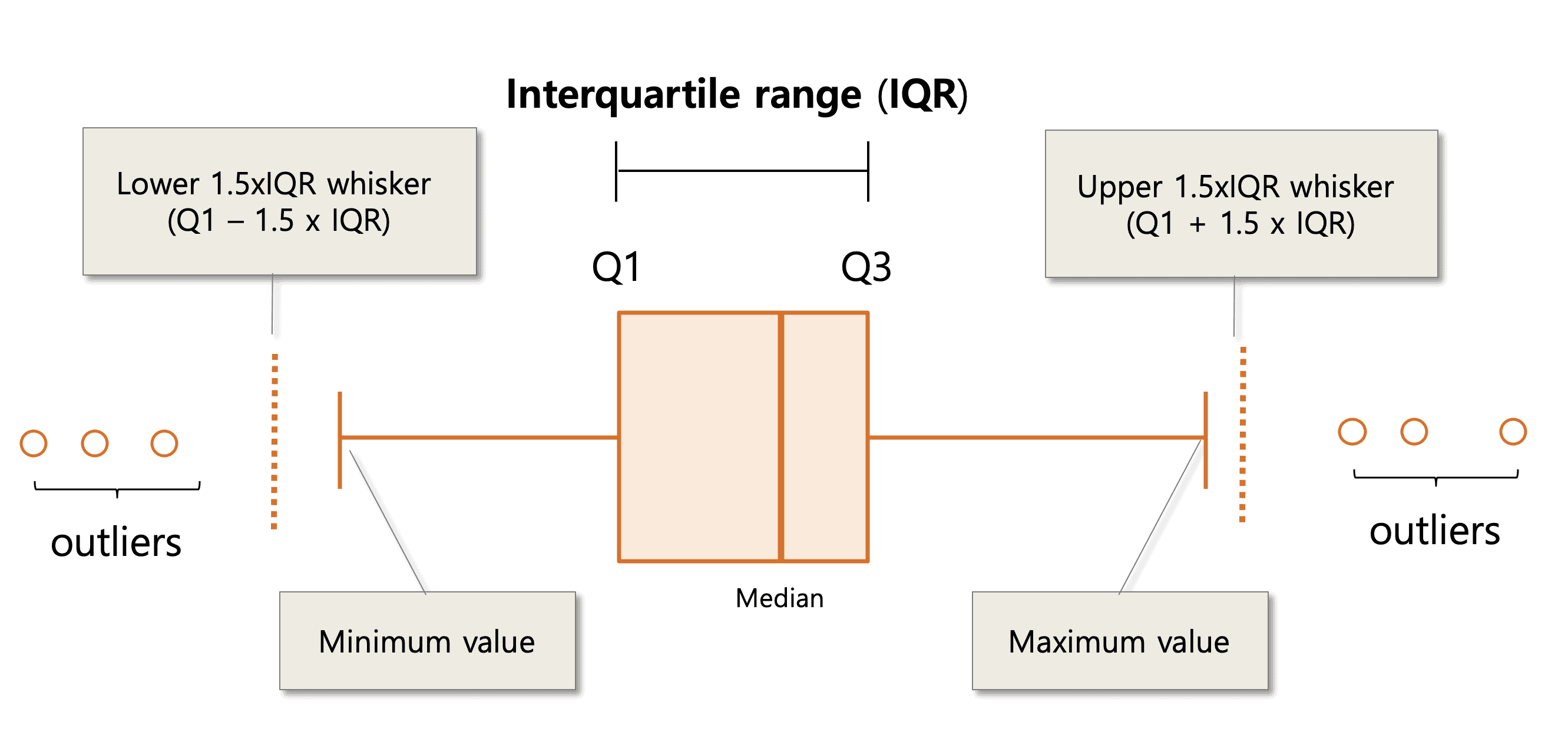
Un boxplot (también conocido como diagrama de caja y bigotes) es una herramienta gráfica utilizada para representar la distribución de un conjunto de datos numéricos a través de su cuartil, valores mínimos y máximos, y outliers (datos extremos).
El boxplot se dibuja a partir de cinco estadísticas descriptivas de los datos:
- El mínimo (valor más pequeño)
- El primer cuartil (Q1) que representa el valor donde el 25% de los datos son menores y el 75% son mayores.
- La mediana (Q2), que representa el valor donde el 50% de los datos son menores y el 50% son mayores.
- El tercer cuartil (Q3) que representa el valor donde el 75% de los datos son menores y el 25% son mayores.
- El máximo (valor más grande).
El boxplot consta de una caja que se extiende desde el primer al tercer cuartil, con una línea en la caja que representa la mediana. Los "bigotes" se extienden desde la caja hasta los valores mínimo y máximo, excluyendo los outliers (datos atípicos), que se grafican como puntos fuera de los bigotes.
# Crear un conjunto de datos aleatorios
data = np.random.normal(0, 1, 1000)
# Crear el boxplot
plt.boxplot(data)
# Agregar etiquetas y título
plt.xlabel('Variable X')
plt.ylabel('Valores')
plt.title('Boxplot de un conjunto de datos aleatorios')
# Mostrar el boxplot
plt.show()

Con el diagrama de boxplot y el histograma, podemos analizar de mejor manera la distribución de nuestra variable.
# Crear un conjunto de datos aleatorios
data = np.random.normal(0, 1, 1000)
# Crear una figura con dos subplots
fig, (ax_box, ax_hist) = plt.subplots(2, sharex=True, gridspec_kw={"height_ratios": (.15, .85)})
# Crear el boxplot
ax_box.boxplot(data, vert=False)
# Crear el histograma
ax_hist.hist(data, bins=10, edgecolor='black')
# Agregar etiquetas y título
ax_box.set(xlabel='Variable X', ylabel='Valores')
ax_hist.set(xlabel='Variable X', ylabel='Frecuencia')
plt.suptitle('Boxplot con histograma')
# Mostrar el gráfico
plt.show()
