import polars as pl
import numpy as npPolars
Introducción
Polars es una librería de DataFrames increíblemente rápida implementada en Rust utilizando Arrow Columnar Format de Apache como modelo de memoria.
- Lazy | eager execution
- Multi-threaded
- SIMD (Single Instruction, Multiple Data)
- Query optimization
- Powerful expression API
- Rust | Python
Esta sección tiene como objetivos presentarle Polars a través de ejemplos y comparándolo con otras soluciones.
Nota: Si usted no esta familiarizado con la manipulación de datos en Python, se recomienda partir leyendo sobre la librería de Pandas. También, se deja como referencia mi curso de Manipulación de Datos.
Primeros Pasos
Instalación
Para instalar Polars, necesitará usar la línea de comando. Si ha instalado Anaconda, puede usar:
conda install -c conda-forge polarsDe lo contrario, puede instalar con pip:
pip install polarsNota: Todos los binarios están preconstruidos para Python v3.6+.
Rendimiento
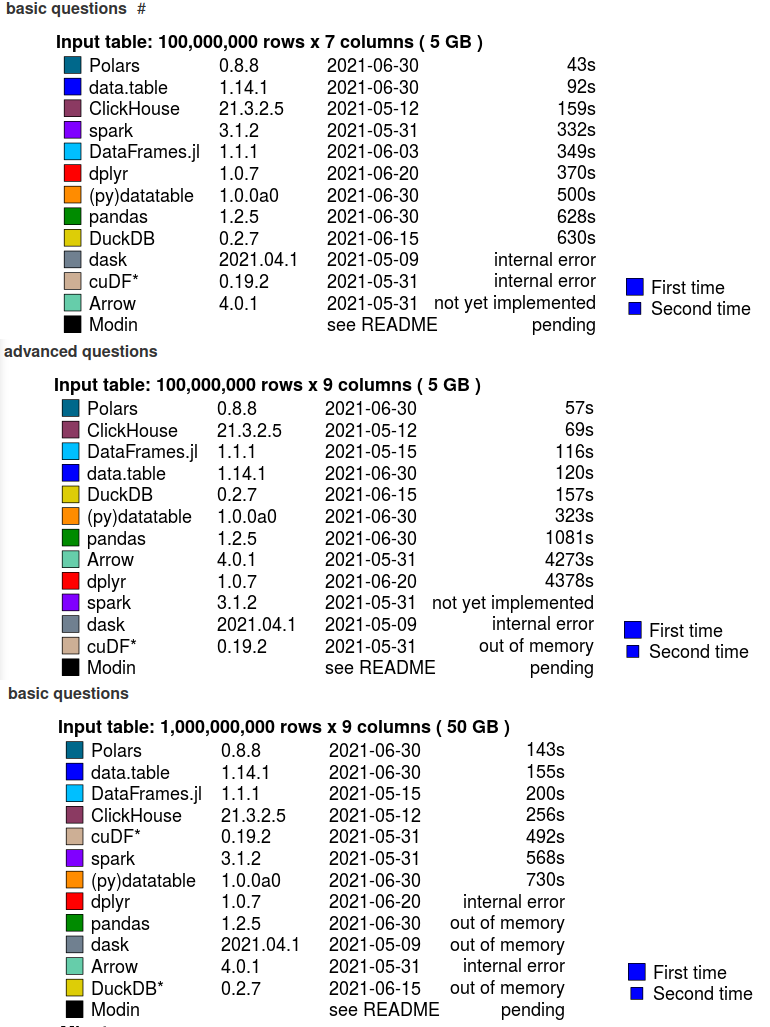
Polars es muy rápido y, de hecho, es una de las mejores soluciones disponibles. Tomemos como referencia db-benchmark de h2oai. Esta página tiene como objetivo comparar varias herramientas similares a bases de datos populares en la ciencia de datos de código abierto. Se ejecuta regularmente con las últimas versiones de estos paquetes y se actualiza automáticamente.
También se incluye la sintaxis que se cronometra junto con el tiempo. De esta manera, puede ver de inmediato si está realizando estas tareas o no, y si las diferencias de tiempo le importan o no. Una diferencia de 10x puede ser irrelevante si eso es solo 1s frente a 0,1s en el tamaño de sus datos.
A modo de ejemplo, veamos algunos ejemplos de performances de distintas librerías para ejecutar distintos tipos de tareas sobre datasets con distintos tamaños. Para el caso de tareas básicas sobre un dataset de 50 GB, Polars supera a librerías espacializadas en distribución de Dataframes como Spark (143 segundos vs 568 segundos). Por otro lado, librerías conocidas en Python como Pandas o Dask se tiene el problema de out of memory.
Expresiones en Polars
Polars tiene un poderoso concepto llamado expresiones. Las expresiones polares se pueden usar en varios contextos y son un mapeo funcional de Fn(Series) -> Series, lo que significa que tienen Series como entrada y Series como salida. Al observar esta definición funcional, podemos ver que la salida de un Expr también puede servir como entrada de un Expr.
Eso puede sonar un poco extraño, así que vamos a dar un ejemplo.
La siguiente es una expresión:
pl.col("foo").sort().head(2)El fragmento anterior dice seleccionar la columna "foo", luego ordenar esta columna y luego tomar los primeros 2 valores de la salida ordenada. El poder de las expresiones es que cada expresión produce una nueva expresión y que se pueden canalizar juntas. Puede ejecutar una expresión pasándola en uno de los contextos de ejecución polares. Aquí ejecutamos dos expresiones ejecutando df.select:
df.select([
pl.col("foo").sort().head(2),
pl.col("barra").filter(pl.col("foo") == 1).sum()
])Todas las expresiones se ejecutan en paralelo. (Tenga en cuenta que dentro de una expresión puede haber más paralelización).
Expresiones
En esta sección veremos algunos ejemplos, pero primero vamos a crear un conjunto de datos:
np.random.seed(12)
df = pl.DataFrame(
{
"nrs": [1, 2, 3, None, 5],
"names": ["foo", "ham", "spam", "egg", None],
"random": np.random.rand(5),
"groups": ["A", "A", "B", "C", "B"],
}
)
print(df)shape: (5, 4)
┌──────┬───────┬──────────┬────────┐
│ nrs ┆ names ┆ random ┆ groups │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str │
╞══════╪═══════╪══════════╪════════╡
│ 1 ┆ foo ┆ 0.154163 ┆ A │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 2 ┆ ham ┆ 0.74 ┆ A │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 3 ┆ spam ┆ 0.263315 ┆ B │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ null ┆ egg ┆ 0.533739 ┆ C │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┤
│ 5 ┆ null ┆ 0.014575 ┆ B │
└──────┴───────┴──────────┴────────┘Puedes hacer mucho con las expresiones, veamos algunos ejemplos:
Contar valores únicos
Podemos contar los valores únicos en una columna. Tenga en cuenta que estamos creando el mismo resultado de diferentes maneras. Para no tener nombres de columna duplicados en el DataFrame, usamos una expresión de alias, que cambia el nombre de una expresión.
out = df.select(
[
pl.col("names").n_unique().alias("unique_names_1"),
pl.col("names").unique().count().alias("unique_names_2"),
]
)
print(out)shape: (1, 2)
┌────────────────┬────────────────┐
│ unique_names_1 ┆ unique_names_2 │
│ --- ┆ --- │
│ u32 ┆ u32 │
╞════════════════╪════════════════╡
│ 5 ┆ 5 │
└────────────────┴────────────────┘Varias agregaciones
Podemos hacer varias agregaciones. A continuación mostramos algunas de ellas, pero hay más, como median, mean, first, etc.
out = df.select(
[
pl.sum("random").alias("sum"),
pl.min("random").alias("min"),
pl.max("random").alias("max"),
pl.col("random").max().alias("other_max"),
pl.std("random").alias("std dev"),
pl.var("random").alias("variance"),
]
)
print(out)shape: (1, 6)
┌──────────┬──────────┬──────┬───────────┬──────────┬──────────┐
│ sum ┆ min ┆ max ┆ other_max ┆ std dev ┆ variance │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ f64 ┆ f64 ┆ f64 ┆ f64 ┆ f64 ┆ f64 │
╞══════════╪══════════╪══════╪═══════════╪══════════╪══════════╡
│ 1.705842 ┆ 0.014575 ┆ 0.74 ┆ 0.74 ┆ 0.293209 ┆ 0.085971 │
└──────────┴──────────┴──────┴───────────┴──────────┴──────────┘Filtro y condicionales
También podemos hacer cosas bastante complejas. En el siguiente fragmento, contamos todos los nombres que terminan con la cadena "am".
out = df.select(
[
pl.col("names").filter(pl.col("names").str.contains(r"am$")).count(),
]
)
print(out)shape: (1, 1)
┌───────┐
│ names │
│ --- │
│ u32 │
╞═══════╡
│ 2 │
└───────┘Funciones binarias y modificación
En el ejemplo a continuación, usamos un condicional para crear una nueva expresión when -> then -> otherwise.
La función when() requiere una expresión de predicado (y, por lo tanto, conduce a una serie booleana), luego espera una expresión que se usará en caso de que el predicado se evalúe como verdadero y, de lo contrario, espera una expresión que se usará en caso de que el predicado se evalúe.
Tenga en cuenta que puede pasar cualquier expresión, o simplemente expresiones base como pl.col("foo"), pl.lit(3), pl.lit("bar"), etc.
Finalmente, multiplicamos esto con el resultado de una expresión de suma.
out = df.select(
[
pl.when(pl.col("random") > 0.5).then(0).otherwise(pl.col("random")) * pl.sum("nrs"),
]
)
print(out)shape: (5, 1)
┌──────────┐
│ literal │
│ --- │
│ f64 │
╞══════════╡
│ 1.695791 │
├╌╌╌╌╌╌╌╌╌╌┤
│ 0.0 │
├╌╌╌╌╌╌╌╌╌╌┤
│ 2.896465 │
├╌╌╌╌╌╌╌╌╌╌┤
│ 0.0 │
├╌╌╌╌╌╌╌╌╌╌┤
│ 0.160325 │
└──────────┘Expresiones de ventana
Una expresión polar también puede hacer un GROUPBY, AGGREGATION y JOIN implícitos en una sola expresión.
En los ejemplos a continuación, hacemos un GROUPBY sobre "groups" y AGREGATE SUM de "random", y en la siguiente expresión GROUPBY OVER "names" y AGREGATE una lista de "random". Estas funciones de ventana se pueden combinar con otras expresiones y son una forma eficaz de determinar estadísticas de grupo. Vea más expresiones en el siguiente link.
out = df[
[
pl.col("*"), # select all
pl.col("random").sum().over("groups").alias("sum[random]/groups"),
pl.col("random").list().over("names").alias("random/name"),
]
]
print(out)shape: (5, 6)
┌──────┬───────┬──────────┬────────┬────────────────────┬─────────────┐
│ nrs ┆ names ┆ random ┆ groups ┆ sum[random]/groups ┆ random/name │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ f64 ┆ str ┆ f64 ┆ list [f64] │
╞══════╪═══════╪══════════╪════════╪════════════════════╪═════════════╡
│ 1 ┆ foo ┆ 0.154163 ┆ A ┆ 0.894213 ┆ [0.154163] │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 2 ┆ ham ┆ 0.74 ┆ A ┆ 0.894213 ┆ [0.74] │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 3 ┆ spam ┆ 0.263315 ┆ B ┆ 0.2778 ┆ [0.263315] │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ null ┆ egg ┆ 0.533739 ┆ C ┆ 0.533739 ┆ [0.533739] │
├╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ 5 ┆ null ┆ 0.014575 ┆ B ┆ 0.2778 ┆ [0.014575] │
└──────┴───────┴──────────┴────────┴────────────────────┴─────────────┘GroupBy
Un enfoque multiproceso
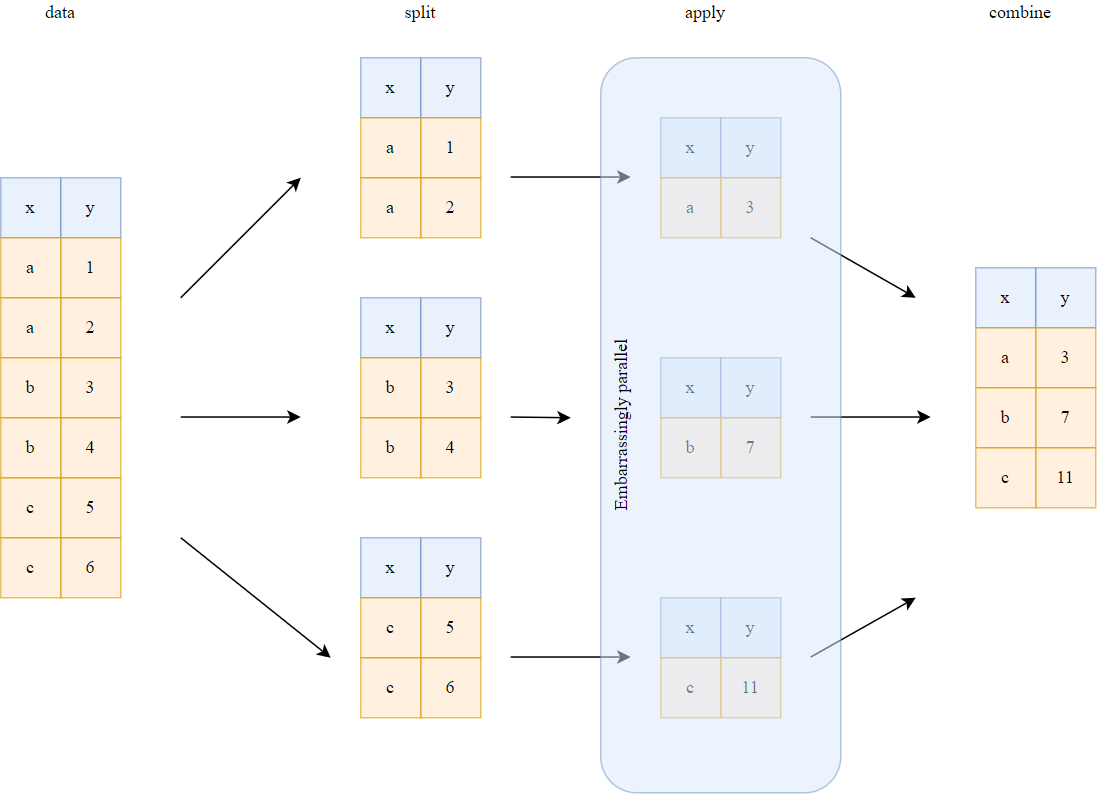
Una de las formas más eficientes de procesar datos tabulares es paralelizar su procesamiento a través del enfoque “dividir-aplicar-combinar”. Esta operación es el núcleo de la implementación del agrupamiento de Polars, lo que le permite lograr operaciones ultrarrápidas. Más específicamente, las fases de “división” y “aplicación” se ejecutan de forma multiproceso.
Una operación de agrupación simple se toma a continuación como ejemplo para ilustrar este enfoque:
Para las operaciones hash realizadas durante la fase de “división”, Polars utiliza un enfoque sin bloqueo de subprocesos múltiples que se ilustra en el siguiente esquema:
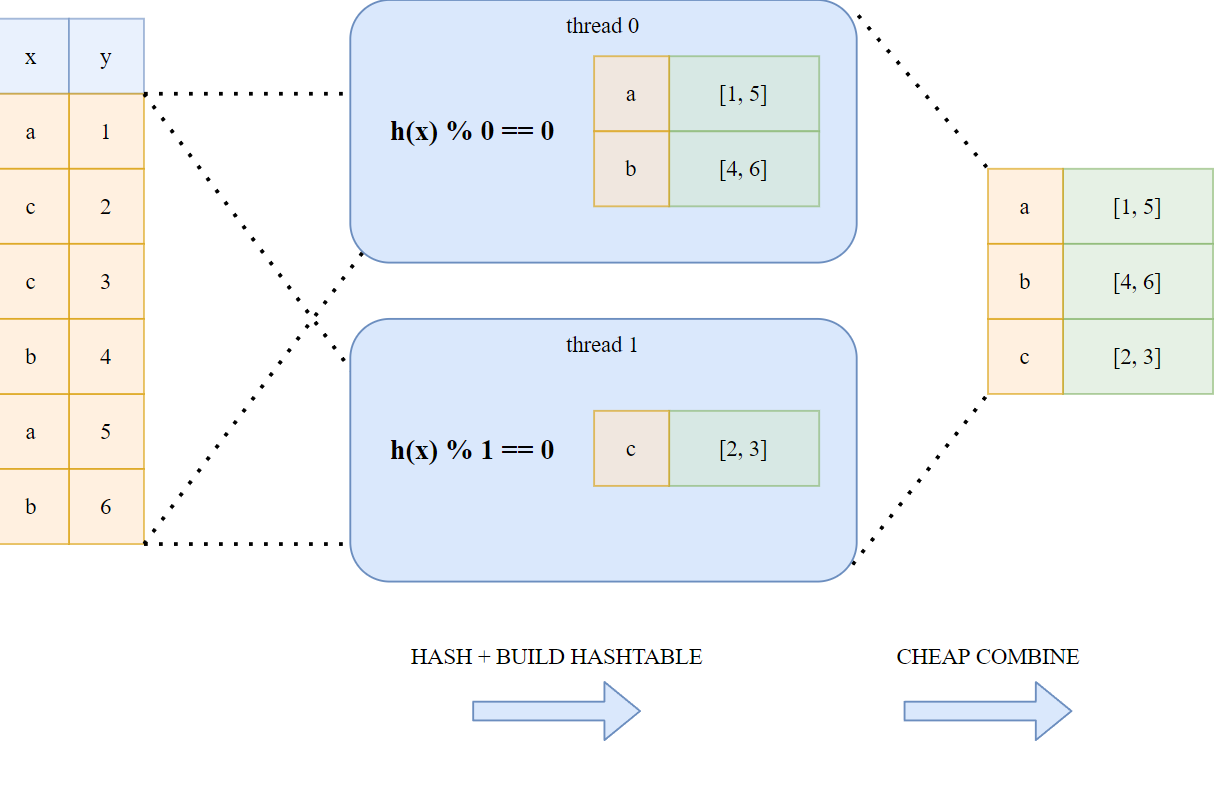
¡Esta paralelización permite que las operaciones de agrupación y unión (por ejemplo) sean increíblemente rápidas!
¡No mates la paralelización!
Todos hemos escuchado que Python es lento y “no escala”. Además de la sobrecarga de ejecutar el código de bytes “lento”, Python debe permanecer dentro de las restricciones del Global interpreter lock (GIL). Esto significa que si se usa la operación lambda o una función de Python personalizada para aplicar durante una fase de paralelización, la velocidad de Polars se limita al ejecutar el código de Python, lo que evita que varios subprocesos ejecuten la función.
Todo esto se siente terriblemente limitante, especialmente porque a menudo necesitamos esos lambda en un paso .groupby(), por ejemplo. Este enfoque aún es compatible con Polars, pero teniendo en cuenta el código de bytes Y el precio GIL deben pagarse.
Para mitigar esto, Polars implementa una poderosa sintaxis definida no solo en su lazy, sino también en su uso eager.
Expresiones polares
En la introducción de la página anterior, discutimos que el uso de funciones personalizadas de Python eliminaba la paralelización y que podemos usar las expresiones de la API diferida para mitigar esto. Echemos un vistazo a lo que eso significa.
Comencemos con el conjunto de datos simple del congreso de EE. UU.
import polars as pl
dataset = pl.read_csv("legislators-current.csv")
dataset = dataset.with_column(pl.col("birthday").str.strptime(pl.Date))
print(dataset.head())shape: (5, 34)
┌───────────┬────────────┬─────────────┬────────┬─────┬────────────────┬────────────────────┬──────────┬────────────────┐
│ last_name ┆ first_name ┆ middle_name ┆ suffix ┆ ... ┆ ballotpedia_id ┆ washington_post_id ┆ icpsr_id ┆ wikipedia_id │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str ┆ ┆ str ┆ str ┆ i64 ┆ str │
╞═══════════╪════════════╪═════════════╪════════╪═════╪════════════════╪════════════════════╪══════════╪════════════════╡
│ Brown ┆ Sherrod ┆ null ┆ null ┆ ... ┆ Sherrod Brown ┆ null ┆ 29389 ┆ Sherrod Brown │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Cantwell ┆ Maria ┆ null ┆ null ┆ ... ┆ Maria Cantwell ┆ null ┆ 39310 ┆ Maria Cantwell │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Cardin ┆ Benjamin ┆ L. ┆ null ┆ ... ┆ Ben Cardin ┆ null ┆ 15408 ┆ Ben Cardin │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Carper ┆ Thomas ┆ Richard ┆ null ┆ ... ┆ Tom Carper ┆ null ┆ 15015 ┆ Tom Carper │
├╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ Casey ┆ Robert ┆ P. ┆ Jr. ┆ ... ┆ Bob Casey, Jr. ┆ null ┆ 40703 ┆ Bob Casey Jr. │
└───────────┴────────────┴─────────────┴────────┴─────┴────────────────┴────────────────────┴──────────┴────────────────┘Agregaciones básicas
Puede combinar fácilmente diferentes agregaciones agregando varias expresiones en una lista. No hay un límite superior en el número de agregaciones que puede hacer y puede hacer cualquier combinación que desee. En el fragmento a continuación, hacemos las siguientes agregaciones:
Por grupo "first_name":
- cuente el número de filas en el grupo:
- forma abreviada:
pl.count("party") - forma completa:
pl.col("party").count()
- forma abreviada:
- agregue el grupo de valores de género a una lista:
- forma completa:
pl.col("gender").list()
- forma completa:
- obtenga el primer valor de la columna
"last_name"en el grupo:- forma abreviada:
pl.primero("last_name") - forma completa:
pl.col("last_name").first()
- forma abreviada:
Además de la agregación, clasificamos inmediatamente el resultado y lo limitamos a los 5 principales para que tengamos un buen resumen general.
q = (
dataset.lazy()
.groupby("first_name")
.agg(
[
pl.count(),
pl.col("gender").list(),
pl.first("last_name"),
]
)
.sort("count", reverse=True)
.limit(5)
)
df = q.collect()
print(df)shape: (5, 4)
┌────────────┬───────┬─────────────────────┬───────────┐
│ first_name ┆ count ┆ gender ┆ last_name │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ list [str] ┆ str │
╞════════════╪═══════╪═════════════════════╪═══════════╡
│ John ┆ 19 ┆ ["M", "M", ... "M"] ┆ Barrasso │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┤
│ Mike ┆ 13 ┆ ["M", "M", ... "M"] ┆ Kelly │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┤
│ Michael ┆ 11 ┆ ["M", "M", ... "M"] ┆ Bennet │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┤
│ David ┆ 11 ┆ ["M", "M", ... "M"] ┆ Cicilline │
├╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌┤
│ James ┆ 9 ┆ ["M", "M", ... "M"] ┆ Inhofe │
└────────────┴───────┴─────────────────────┴───────────┘Condicionales
Ok, eso fue bastante fácil, ¿verdad? Subamos un nivel. Digamos que queremos saber cuántos delegados de un “estado” (state) son administración “Democrat” o “Republican”. Podríamos consultarlo directamente en la agregación sin la necesidad de lambda o arreglar el DataFrame.
q = (
dataset.lazy()
.groupby("state")
.agg(
[
(pl.col("party") == "Democrat").sum().alias("demo"),
(pl.col("party") == "Republican").sum().alias("repu"),
]
)
.sort("demo", reverse=True)
.limit(5)
)
df = q.collect()
print(df)shape: (5, 3)
┌───────┬──────┬──────┐
│ state ┆ demo ┆ repu │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ u32 │
╞═══════╪══════╪══════╡
│ CA ┆ 44 ┆ 10 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ NY ┆ 21 ┆ 8 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ IL ┆ 15 ┆ 5 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ TX ┆ 13 ┆ 25 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌┼╌╌╌╌╌╌┤
│ NJ ┆ 12 ┆ 2 │
└───────┴──────┴──────┘Por supuesto, también se podría hacer algo similar con un GROUPBY anidado, pero eso no me permitiría mostrar estas características agradables. 😉
q = (
dataset.lazy()
.groupby(["state", "party"])
.agg([pl.count("party").alias("count")])
.filter((pl.col("party") == "Democrat") | (pl.col("party") == "Republican"))
.sort("count", reverse=True)
.limit(5)
)
df = q.collect()
print(df)shape: (5, 3)
┌───────┬────────────┬───────┐
│ state ┆ party ┆ count │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ u32 │
╞═══════╪════════════╪═══════╡
│ CA ┆ Democrat ┆ 44 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┤
│ TX ┆ Republican ┆ 25 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┤
│ NY ┆ Democrat ┆ 21 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┤
│ FL ┆ Republican ┆ 18 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌┤
│ IL ┆ Democrat ┆ 15 │
└───────┴────────────┴───────┘Filtración
También podemos filtrar los grupos. Digamos que queremos calcular una media por grupo, pero no queremos incluir todos los valores de ese grupo y tampoco queremos filtrar las filas del DataFrame (porque necesitamos esas filas para otra agregación).
En el siguiente ejemplo, mostramos cómo se puede hacer eso. Tenga en cuenta que podemos hacer funciones de Python para mayor claridad. Estas funciones no nos cuestan nada. Esto se debe a que solo creamos Polars expression, no aplicamos una función personalizada sobre Series durante el tiempo de ejecución de la consulta.
from datetime import date
def compute_age() -> pl.Expr:
return date(2021, 1, 1).year - pl.col("birthday").dt.year()
def avg_birthday(gender: str) -> pl.Expr:
return compute_age().filter(pl.col("gender") == gender).mean().alias(f"avg {gender} birthday")q = (
dataset.lazy()
.groupby(["state"])
.agg(
[
avg_birthday("M"),
avg_birthday("F"),
(pl.col("gender") == "M").sum().alias("# male"),
(pl.col("gender") == "F").sum().alias("# female"),
]
)
.limit(5)
)
df = q.collect()
print(df)shape: (5, 5)
┌───────┬────────────────┬────────────────┬────────┬──────────┐
│ state ┆ avg M birthday ┆ avg F birthday ┆ # male ┆ # female │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ f64 ┆ u32 ┆ u32 │
╞═══════╪════════════════╪════════════════╪════════╪══════════╡
│ MS ┆ 60.0 ┆ 62.0 ┆ 5 ┆ 1 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┤
│ NV ┆ 55.5 ┆ 61.75 ┆ 2 ┆ 4 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┤
│ KS ┆ 54.2 ┆ 41.0 ┆ 5 ┆ 1 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┤
│ IN ┆ 55.0 ┆ 50.5 ┆ 9 ┆ 2 │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌┤
│ IL ┆ 60.923077 ┆ 58.428571 ┆ 13 ┆ 7 │
└───────┴────────────────┴────────────────┴────────┴──────────┘Sorting
A menudo veo que se ordena un DataFrame con el único propósito de ordenar durante la operación GROUPBY. Digamos que queremos obtener los nombres de los políticos más antiguos y más jóvenes (no es que todavía estén vivos) por estado, podríamos ORDENAR y AGRUPAR.
def get_person() -> pl.Expr:
return pl.col("first_name") + pl.lit(" ") + pl.col("last_name")
q = (
dataset.lazy()
.sort("birthday")
.groupby(["state"])
.agg(
[
get_person().first().alias("youngest"),
get_person().last().alias("oldest"),
]
)
.limit(5)
)
df = q.collect()
print(df)shape: (5, 3)
┌───────┬──────────────────────────┬──────────────────────────┐
│ state ┆ youngest ┆ oldest │
│ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str │
╞═══════╪══════════════════════════╪══════════════════════════╡
│ PR ┆ Jenniffer González-Colón ┆ Jenniffer González-Colón │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ ND ┆ John Hoeven ┆ Kelly Armstrong │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ KY ┆ Harold Rogers ┆ Garland Barr │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ NM ┆ Teresa Leger Fernandez ┆ Melanie Stansbury │
├╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┼╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┤
│ OR ┆ Peter DeFazio ┆ Jeff Merkley │
└───────┴──────────────────────────┴──────────────────────────┘