
Getting Started With SQL and BigQuery¶
Introduction¶
Structured Query Language, or SQL, is the programming language used with databases, and it is an important skill for any data scientist. In this course, you'll build your SQL skills using BigQuery, a web service that lets you apply SQL to huge datasets.
In this lesson, you'll learn the basics of accessing and examining BigQuery datasets. After you have a handle on these basics, we'll come back to build your SQL skills.
Your first BigQuery commands¶
To use BigQuery, we'll import the Python package below:
from google.cloud import bigquery
The first step in the workflow is to create a Client object. As you'll soon see, this Client object will play a central role in retrieving information from BigQuery datasets.
# Create a "Client" object
client = bigquery.Client()
Using Kaggle's public dataset BigQuery integration.
We'll work with a dataset of posts on Hacker News, a website focusing on computer science and cybersecurity news.
In BigQuery, each dataset is contained in a corresponding project. In this case, our hacker_news dataset is contained in the bigquery-public-data project. To access the dataset,
- We begin by constructing a reference to the dataset with the
dataset()method. - Next, we use the
get_dataset()method, along with the reference we just constructed, to fetch the dataset.
# Construct a reference to the "hacker_news" dataset
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
Every dataset is just a collection of tables. You can think of a dataset as a spreadsheet file containing multiple tables, all composed of rows and columns.
We use the list_tables() method to list the tables in the dataset.
# List all the tables in the "hacker_news" dataset
tables = list(client.list_tables(dataset))
# Print names of all tables in the dataset (there are four!)
for table in tables:
print(table.table_id)
comments full full_201510 stories
Similar to how we fetched a dataset, we can fetch a table. In the code cell below, we fetch the full table in the hacker_news dataset.
# Construct a reference to the "full" table
table_ref = dataset_ref.table("full")
# API request - fetch the table
table = client.get_table(table_ref)
In the next section, you'll explore the contents of this table in more detail. For now, take the time to use the image below to consolidate what you've learned so far.
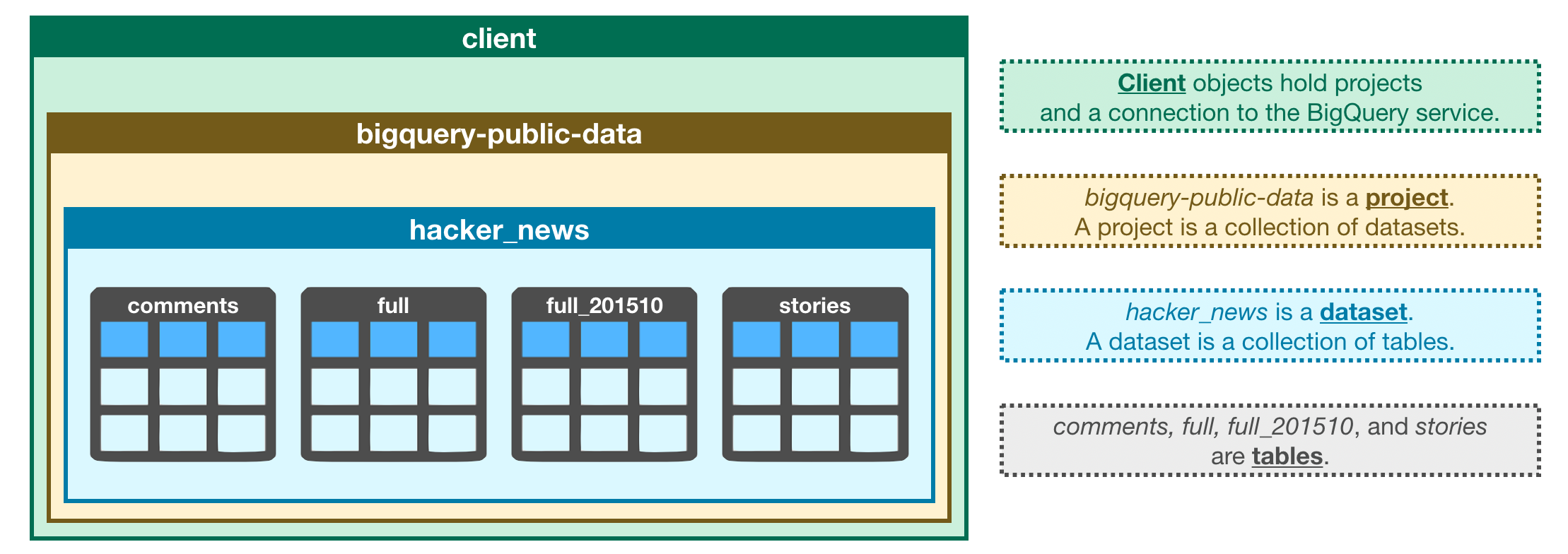
Table schema¶
The structure of a table is called its schema. We need to understand a table's schema to effectively pull out the data we want.
In this example, we'll investigate the full table that we fetched above.
# Print information on all the columns in the "full" table in the "hacker_news" dataset
table.schema
[SchemaField('title', 'STRING', 'NULLABLE', 'Story title', (), None),
SchemaField('url', 'STRING', 'NULLABLE', 'Story url', (), None),
SchemaField('text', 'STRING', 'NULLABLE', 'Story or comment text', (), None),
SchemaField('dead', 'BOOLEAN', 'NULLABLE', 'Is dead?', (), None),
SchemaField('by', 'STRING', 'NULLABLE', "The username of the item's author.", (), None),
SchemaField('score', 'INTEGER', 'NULLABLE', 'Story score', (), None),
SchemaField('time', 'INTEGER', 'NULLABLE', 'Unix time', (), None),
SchemaField('timestamp', 'TIMESTAMP', 'NULLABLE', 'Timestamp for the unix time', (), None),
SchemaField('type', 'STRING', 'NULLABLE', 'Type of details (comment, comment_ranking, poll, story, job, pollopt)', (), None),
SchemaField('id', 'INTEGER', 'NULLABLE', "The item's unique id.", (), None),
SchemaField('parent', 'INTEGER', 'NULLABLE', 'Parent comment ID', (), None),
SchemaField('descendants', 'INTEGER', 'NULLABLE', 'Number of story or poll descendants', (), None),
SchemaField('ranking', 'INTEGER', 'NULLABLE', 'Comment ranking', (), None),
SchemaField('deleted', 'BOOLEAN', 'NULLABLE', 'Is deleted?', (), None)]
Each SchemaField tells us about a specific column (which we also refer to as a field). In order, the information is:
- The name of the column
- The field type (or datatype) in the column
- The mode of the column (
'NULLABLE'means that a column allows NULL values, and is the default) - A description of the data in that column
The first field has the SchemaField:
SchemaField('by', 'string', 'NULLABLE', "The username of the item's author.",())
This tells us:
- the field (or column) is called
by, - the data in this field is strings,
- NULL values are allowed, and
- it contains the usernames corresponding to each item's author.
We can use the list_rows() method to check just the first five lines of of the full table to make sure this is right. (Sometimes databases have outdated descriptions, so it's good to check.) This returns a BigQuery RowIterator object that can quickly be converted to a pandas DataFrame with the to_dataframe() method.
# Preview the first five lines of the "full" table
client.list_rows(table, max_results=5).to_dataframe()
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:2: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| title | url | text | dead | by | score | time | timestamp | type | id | parent | descendants | ranking | deleted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | None | > Are you really going to argue that "... | None | Domenic_S | NaN | 1422154497 | 2015-01-25 02:54:57+00:00 | comment | 8941906 | 8941871 | NaN | NaN | None |
| 1 | None | None | My doc prescribed me 25,000 IU once a week for... | None | ryanmarsh | NaN | 1512668114 | 2017-12-07 17:35:14+00:00 | comment | 15872018 | 15870676 | NaN | NaN | None |
| 2 | None | None | All of this is anecdotal:<p>These past couple ... | None | Snackchez | NaN | 1512668115 | 2017-12-07 17:35:15+00:00 | comment | 15872019 | 15871723 | NaN | NaN | None |
| 3 | None | None | I don't know if anybody else has ever wit... | None | Glyptodon | NaN | 1383839755 | 2013-11-07 15:55:55+00:00 | comment | 6690041 | 6689591 | NaN | NaN | None |
| 4 | None | None | We have to remember that the NFL, after everyt... | None | zcdziura | NaN | 1422154427 | 2015-01-25 02:53:47+00:00 | comment | 8941903 | 8941712 | NaN | NaN | None |
The list_rows() method will also let us look at just the information in a specific column. If we want to see the first five entries in the by column, for example, we can do that!
# Preview the first five entries in the "by" column of the "full" table
client.list_rows(table, selected_fields=table.schema[:1], max_results=5).to_dataframe()
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:2: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| title | |
|---|---|
| 0 | None |
| 1 | None |
| 2 | None |
| 3 | None |
| 4 | None |
Disclaimer¶
Before we go into the coding exercise, a quick disclaimer for those who already know some SQL:
Each Kaggle user can scan 5TB every 30 days for free. Once you hit that limit, you'll have to wait for it to reset.
The commands you've seen so far won't demand a meaningful fraction of that limit. But some BiqQuery datasets are huge. So, if you already know SQL, wait to run SELECT queries until you've seen how to use your allotment effectively. If you are like most people reading this, you don't know how to write these queries yet, so you don't need to worry about this disclaimer.
Your turn¶
Practice the commands you've seen to explore the structure of a dataset with crimes in the city of Chicago.
Have questions or comments? Visit the course discussion forum to chat with other learners.