
Select, From & Where¶
Introduction¶
Now that you know how to access and examine a dataset, you're ready to write your first SQL query! As you'll soon see, SQL queries will help you sort through a massive dataset, to retrieve only the information that you need.
We'll begin by using the keywords SELECT, FROM, and WHERE to get data from specific columns based on conditions you specify.
For clarity, we'll work with a small imaginary dataset pet_records which contains just one table, called pets.
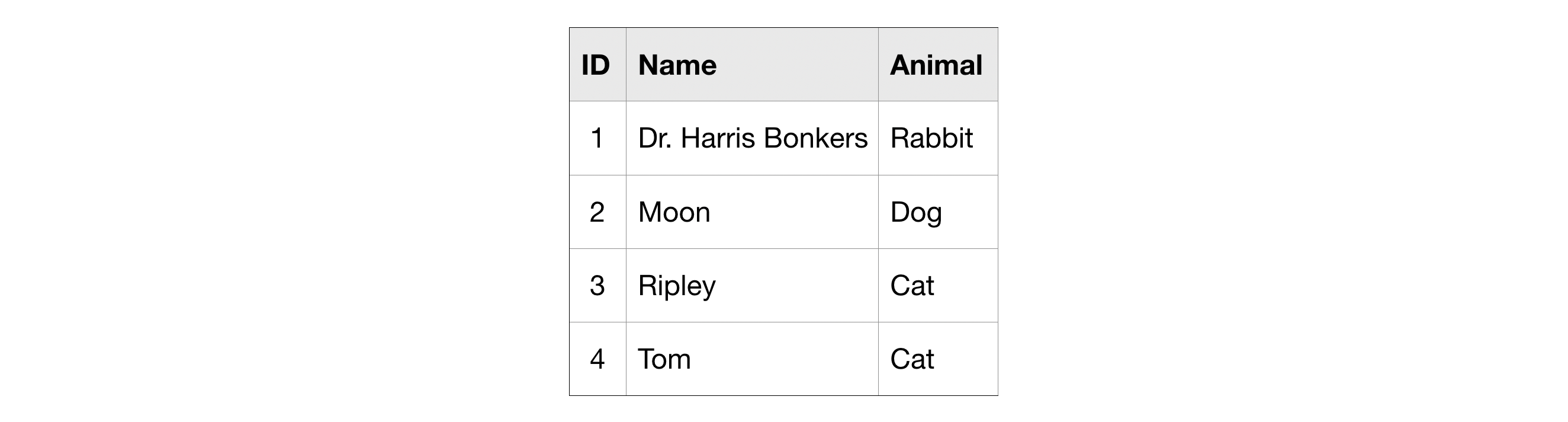
SELECT ... FROM¶
The most basic SQL query selects a single column from a single table. To do this,
- specify the column you want after the word SELECT, and then
- specify the table after the word FROM.
For instance, to select the Name column (from the pets table in the pet_records database in the bigquery-public-data project), our query would appear as follows:

Note that when writing an SQL query, the argument we pass to FROM is not in single or double quotation marks (' or "). It is in backticks (`).
WHERE ...¶
BigQuery datasets are large, so you'll usually want to return only the rows meeting specific conditions. You can do this using the WHERE clause.
The query below returns the entries from the Name column that are in rows where the Animal column has the text 'Cat'.

Example: What are all the U.S. cities in the OpenAQ dataset?¶
Now that you've got the basics down, let's work through an example with a real dataset. We'll use an OpenAQ dataset about air quality.
First, we'll set up everything we need to run queries and take a quick peek at what tables are in our database. (Since you learned how to do this in the previous tutorial, we have hidden the code. But if you'd like to take a peek, you need only click on the "Code" button below.)
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "openaq" dataset
dataset_ref = client.dataset("openaq", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# List all the tables in the "openaq" dataset
tables = list(client.list_tables(dataset))
# Print names of all tables in the dataset (there's only one!)
for table in tables:
print(table.table_id)
Using Kaggle's public dataset BigQuery integration. global_air_quality
The dataset contains only one table, called global_air_quality. We'll fetch the table and take a peek at the first few rows to see what sort of data it contains. (Again, we have hidden the code. To take a peek, click on the "Code" button below.)
# Construct a reference to the "global_air_quality" table
table_ref = dataset_ref.table("global_air_quality")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the "global_air_quality" table
client.list_rows(table, max_results=5).to_dataframe()
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:8: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| location | city | country | pollutant | value | timestamp | unit | source_name | latitude | longitude | averaged_over_in_hours | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BTM Layout, Bengaluru - KSPCB | Bengaluru | IN | co | 910.00 | 2018-02-22 03:00:00+00:00 | µg/m³ | CPCB | 12.912811 | 77.60922 | 0.25 |
| 1 | BTM Layout, Bengaluru - KSPCB | Bengaluru | IN | no2 | 131.87 | 2018-02-22 03:00:00+00:00 | µg/m³ | CPCB | 12.912811 | 77.60922 | 0.25 |
| 2 | BTM Layout, Bengaluru - KSPCB | Bengaluru | IN | o3 | 15.57 | 2018-02-22 03:00:00+00:00 | µg/m³ | CPCB | 12.912811 | 77.60922 | 0.25 |
| 3 | BTM Layout, Bengaluru - KSPCB | Bengaluru | IN | pm25 | 45.62 | 2018-02-22 03:00:00+00:00 | µg/m³ | CPCB | 12.912811 | 77.60922 | 0.25 |
| 4 | BTM Layout, Bengaluru - KSPCB | Bengaluru | IN | so2 | 4.49 | 2018-02-22 03:00:00+00:00 | µg/m³ | CPCB | 12.912811 | 77.60922 | 0.25 |
Everything looks good! So, let's put together a query. Say we want to select all the values from the city column that are in rows where the country column is 'US' (for "United States").
# Query to select all the items from the "city" column where the "country" column is 'US'
query = """
SELECT city
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""
# Create a "Client" object
client = bigquery.Client()
Using Kaggle's public dataset BigQuery integration.
We begin by setting up the query with the query() method. We run the method with the default parameters, but this method also allows us to specify more complicated settings that you can read about in the documentation. We'll revisit this later.
# Set up the query
query_job = client.query(query)
Next, we run the query and convert the results to a pandas DataFrame.
# API request - run the query, and return a pandas DataFrame
us_cities = query_job.to_dataframe()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
Now we've got a pandas DataFrame called us_cities, which we can use like any other DataFrame.
# What five cities have the most measurements?
us_cities.city.value_counts().head()
Phoenix-Mesa-Scottsdale 88 Houston 82 Los Angeles-Long Beach-Santa Ana 68 Riverside-San Bernardino-Ontario 60 New York-Northern New Jersey-Long Island 60 Name: city, dtype: int64
More queries¶
If you want multiple columns, you can select them with a comma between the names:
query = """
SELECT city, country
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""
You can select all columns with a * like this:
query = """
SELECT *
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""
Q&A: Notes on formatting¶
The formatting of the SQL query might feel unfamiliar. If you have any questions, you can ask in the comments section at the bottom of this page. Here are answers to two common questions:
Question: What's up with the triple quotation marks (""")?¶
Answer: These tell Python that everything inside them is a single string, even though we have line breaks in it. The line breaks aren't necessary, but they make it easier to read your query.
Question: Do you need to capitalize SELECT and FROM?¶
Answer: No, SQL doesn't care about capitalization. However, it's customary to capitalize your SQL commands, and it makes your queries a bit easier to read.
Working with big datasets¶
BigQuery datasets can be huge. We allow you to do a lot of computation for free, but everyone has some limit.
Each Kaggle user can scan 5TB every 30 days for free. Once you hit that limit, you'll have to wait for it to reset.
The biggest dataset currently on Kaggle is 3TB, so you can go through your 30-day limit in a couple queries if you aren't careful.
Don't worry though: we'll teach you how to avoid scanning too much data at once, so that you don't run over your limit.
To begin,you can estimate the size of any query before running it. Here is an example using the (very large!) Hacker News dataset. To see how much data a query will scan, we create a QueryJobConfig object and set the dry_run parameter to True.
# Query to get the score column from every row where the type column has value "job"
query = """
SELECT score, title
FROM `bigquery-public-data.hacker_news.full`
WHERE type = "job"
"""
# Create a QueryJobConfig object to estimate size of query without running it
dry_run_config = bigquery.QueryJobConfig(dry_run=True)
# API request - dry run query to estimate costs
dry_run_query_job = client.query(query, job_config=dry_run_config)
print("This query will process {} bytes.".format(dry_run_query_job.total_bytes_processed))
This query will process 494391991 bytes.
You can also specify a parameter when running the query to limit how much data you are willing to scan. Here's an example with a low limit.
# Only run the query if it's less than 1 MB
ONE_MB = 1000*1000
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=ONE_MB)
# Set up the query (will only run if it's less than 1 MB)
safe_query_job = client.query(query, job_config=safe_config)
# API request - try to run the query, and return a pandas DataFrame
safe_query_job.to_dataframe()
--------------------------------------------------------------------------- InternalServerError Traceback (most recent call last) /tmp/ipykernel_21/2063017411.py in <module> 7 8 # API request - try to run the query, and return a pandas DataFrame ----> 9 safe_query_job.to_dataframe() /opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/job.py in to_dataframe(self, bqstorage_client, dtypes, progress_bar_type, create_bqstorage_client, date_as_object) 3403 ValueError: If the `pandas` library cannot be imported. 3404 """ -> 3405 return self.result().to_dataframe( 3406 bqstorage_client=bqstorage_client, 3407 dtypes=dtypes, /opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/job.py in result(self, page_size, max_results, retry, timeout, start_index) 3232 """ 3233 try: -> 3234 super(QueryJob, self).result(retry=retry, timeout=timeout) 3235 3236 # Return an iterator instead of returning the job. /opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/job.py in result(self, retry, timeout) 819 self._begin(retry=retry, timeout=timeout) 820 # TODO: modify PollingFuture so it can pass a retry argument to done(). --> 821 return super(_AsyncJob, self).result(timeout=timeout) 822 823 def cancelled(self): /opt/conda/lib/python3.7/site-packages/google/api_core/future/polling.py in result(self, timeout, retry) 133 # pylint: disable=raising-bad-type 134 # Pylint doesn't recognize that this is valid in this case. --> 135 raise self._exception 136 137 return self._result InternalServerError: 500 Query exceeded limit for bytes billed: 1000000. 494927872 or higher required. (job ID: 89759fc8-1481-4761-b263-74fab214ded1) -----Query Job SQL Follows----- | . | . | . | . | . | 1: 2: SELECT score, title 3: FROM `bigquery-public-data.hacker_news.full` 4: WHERE type = "job" 5: | . | . | . | . | . |
In this case, the query was cancelled, because the limit of 1 MB was exceeded. However, we can increase the limit to run the query successfully!
# Only run the query if it's less than 1 GB
ONE_GB = 1000*1000*1000
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=ONE_GB)
# Set up the query (will only run if it's less than 1 GB)
safe_query_job = client.query(query, job_config=safe_config)
# API request - try to run the query, and return a pandas DataFrame
job_post_scores = safe_query_job.to_dataframe()
# Print average score for job posts
job_post_scores.score.mean()
1.7846262840949345
Your turn¶
Writing SELECT statements is the key to using SQL. So try your new skills!
Have questions or comments? Visit the course discussion forum to chat with other learners.