
Group By, Having & Count¶
Introduction¶
Now that you can select raw data, you're ready to learn how to group your data and count things within those groups. This can help you answer questions like:
- How many of each kind of fruit has our store sold?
- How many species of animal has the vet office treated?
To do this, you'll learn about three new techniques: GROUP BY, HAVING and COUNT(). Once again, we'll use this made-up table of information on pets.
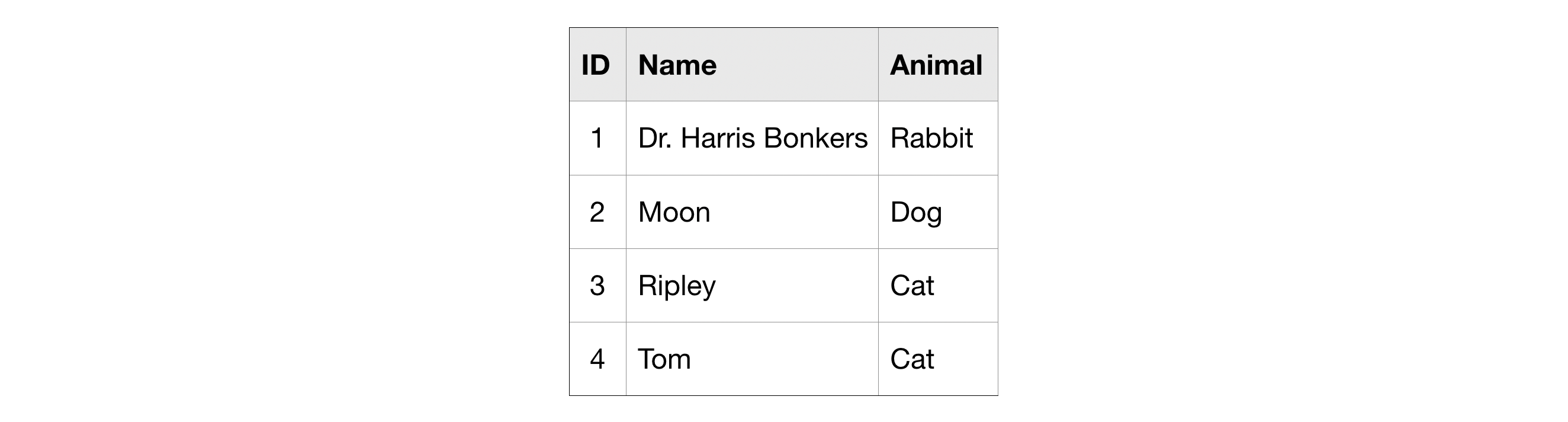
COUNT()¶
COUNT(), as you may have guessed from the name, returns a count of things. If you pass it the name of a column, it will return the number of entries in that column.
For instance, if we SELECT the COUNT() of the ID column in the pets table, it will return 4, because there are 4 ID's in the table.

COUNT() is an example of an aggregate function, which takes many values and returns one. (Other examples of aggregate functions include SUM(), AVG(), MIN(), and MAX().) As you'll notice in the picture above, aggregate functions introduce strange column names (like f0__). Later in this tutorial, you'll learn how to change the name to something more descriptive.
GROUP BY¶
GROUP BY takes the name of one or more columns, and treats all rows with the same value in that column as a single group when you apply aggregate functions like COUNT().
For example, say we want to know how many of each type of animal we have in the pets table. We can use GROUP BY to group together rows that have the same value in the Animal column, while using COUNT() to find out how many ID's we have in each group.

It returns a table with three rows (one for each distinct animal). We can see that the pets table contains 1 rabbit, 1 dog, and 2 cats.
GROUP BY ... HAVING¶
HAVING is used in combination with GROUP BY to ignore groups that don't meet certain criteria.
So this query, for example, will only include groups that have more than one ID in them.

Since only one group meets the specified criterion, the query will return a table with only one row.
Example: Which Hacker News comments generated the most discussion?¶
Ready to see an example on a real dataset? The Hacker News dataset contains information on stories and comments from the Hacker News social networking site.
We'll work with the comments table and begin by printing the first few rows. (We have hidden the corresponding code. To take a peek, click on the "Code" button below.)
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "hacker_news" dataset
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "comments" table
table_ref = dataset_ref.table("comments")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the "comments" table
client.list_rows(table, max_results=5).to_dataframe()
Using Kaggle's public dataset BigQuery integration.
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:19: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| id | by | author | time | time_ts | text | parent | deleted | dead | ranking | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2701393 | 5l | 5l | 1309184881 | 2011-06-27 14:28:01+00:00 | And the glazier who fixed all the broken windo... | 2701243 | None | None | 0 |
| 1 | 5811403 | 99 | 99 | 1370234048 | 2013-06-03 04:34:08+00:00 | Does canada have the equivalent of H1B/Green c... | 5804452 | None | None | 0 |
| 2 | 21623 | AF | AF | 1178992400 | 2007-05-12 17:53:20+00:00 | Speaking of Rails, there are other options in ... | 21611 | None | None | 0 |
| 3 | 10159727 | EA | EA | 1441206574 | 2015-09-02 15:09:34+00:00 | Humans and large livestock (and maybe even pet... | 10159396 | None | None | 0 |
| 4 | 2988424 | Iv | Iv | 1315853580 | 2011-09-12 18:53:00+00:00 | I must say I reacted in the same way when I re... | 2988179 | None | None | 0 |
Let's use the table to see which comments generated the most replies. Since:
- the
parentcolumn indicates the comment that was replied to, and - the
idcolumn has the unique ID used to identify each comment,
we can GROUP BY the parent column and COUNT() the id column in order to figure out the number of comments that were made as responses to a specific comment. (This might not make sense immediately -- take your time here to ensure that everything is clear!)
Furthermore, since we're only interested in popular comments, we'll look at comments with more than ten replies. So, we'll only return groups HAVING more than ten ID's.
# Query to select comments that received more than 10 replies
query_popular = """
SELECT parent, COUNT(id)
FROM `bigquery-public-data.hacker_news.comments`
GROUP BY parent
HAVING COUNT(id) > 10
"""
Now that our query is ready, let's run it and store the results in a pandas DataFrame:
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query_popular, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
popular_comments = query_job.to_dataframe()
# Print the first five rows of the DataFrame
popular_comments.head()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
| parent | f0_ | |
|---|---|---|
| 0 | 7021664 | 40 |
| 1 | 7213378 | 61 |
| 2 | 4325231 | 62 |
| 3 | 8979886 | 38 |
| 4 | 8399209 | 40 |
Each row in the popular_comments DataFrame corresponds to a comment that received more than ten replies. For instance, the comment with ID 801208 received 56 replies.
Aliasing and other improvements¶
A couple hints to make your queries even better:
- The column resulting from
COUNT(id)was calledf0__. That's not a very descriptive name. You can change the name by addingAS NumPostsafter you specify the aggregation. This is called aliasing, and it will be covered in more detail in an upcoming lesson. - If you are ever unsure what to put inside the COUNT() function, you can do
COUNT(1)to count the rows in each group. Most people find it especially readable, because we know it's not focusing on other columns. It also scans less data than if supplied column names (making it faster and using less of your data access quota).
Using these tricks, we can rewrite our query:
# Improved version of earlier query, now with aliasing & improved readability
query_improved = """
SELECT parent, COUNT(1) AS NumPosts
FROM `bigquery-public-data.hacker_news.comments`
GROUP BY parent
HAVING COUNT(1) > 10
"""
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query_improved, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
improved_df = query_job.to_dataframe()
# Print the first five rows of the DataFrame
improved_df.head()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
| parent | NumPosts | |
|---|---|---|
| 0 | 7536283 | 45 |
| 1 | 4053076 | 242 |
| 2 | 2530963 | 59 |
| 3 | 1934367 | 70 |
| 4 | 8204007 | 43 |
Now you have the data you want, and it has descriptive names. That's good style.
Note on using GROUP BY¶
Note that because it tells SQL how to apply aggregate functions (like COUNT()), it doesn't make sense to use GROUP BY without an aggregate function. Similarly, if you have any GROUP BY clause, then all variables must be passed to either a
- GROUP BY command, or
- an aggregation function.
Consider the query below:
query_good = """
SELECT parent, COUNT(id)
FROM `bigquery-public-data.hacker_news.comments`
GROUP BY parent
"""
Note that there are two variables: parent and id.
parentwas passed to a GROUP BY command (inGROUP BY parent), andidwas passed to an aggregate function (inCOUNT(id)).
And this query won't work, because the author column isn't passed to an aggregate function or a GROUP BY clause:
query_bad = """
SELECT author, parent, COUNT(id)
FROM `bigquery-public-data.hacker_news.comments`
GROUP BY parent
"""
If make this error, you'll get the error message SELECT list expression references column (column's name) which is neither grouped nor aggregated at.
Your turn¶
These aggregations let you write much more interesting queries. Try it yourself with these coding exercises.
Have questions or comments? Visit the course discussion forum to chat with other learners.