
As & With¶
Introduction¶
With all that you've learned, your SQL queries are getting pretty long, which can make them hard understand (and debug).
You are about to learn how to use AS and WITH to tidy up your queries and make them easier to read.
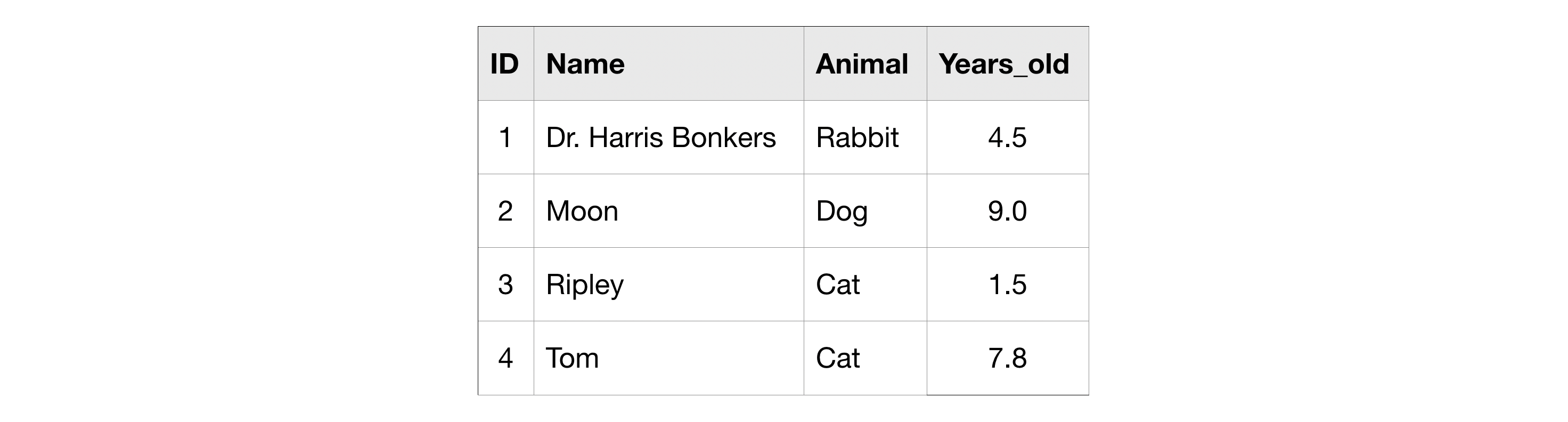
Along the way, we'll use the familiar pets table, but now it includes the ages of the animals.
AS¶
You learned in an earlier tutorial how to use AS to rename the columns generated by your queries, which is also known as aliasing. This is similar to how Python uses as for aliasing when doing imports like import pandas as pd or import seaborn as sns.
To use AS in SQL, insert it right after the column you select. Here's an example of a query without an AS clause:

And here's an example of the same query, but with AS.

These queries return the same information, but in the second query the column returned by the COUNT() function will be called Number, rather than the default name of f0__.
WITH ... AS¶
On its own, AS is a convenient way to clean up the data returned by your query. It's even more powerful when combined with WITH in what's called a "common table expression".
A common table expression (or CTE) is a temporary table that you return within your query. CTEs are helpful for splitting your queries into readable chunks, and you can write queries against them.
For instance, you might want to use the pets table to ask questions about older animals in particular. So you can start by creating a CTE which only contains information about animals more than five years old like this:
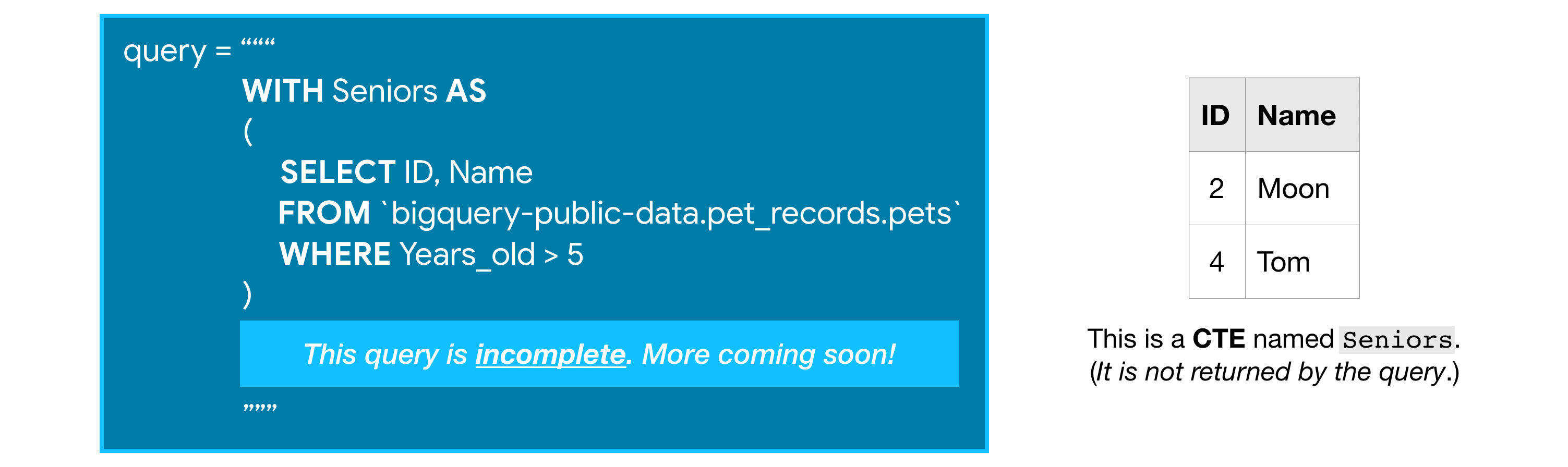
While this incomplete query above won't return anything, it creates a CTE that we can then refer to (as Seniors) while writing the rest of the query.
We can finish the query by pulling the information that we want from the CTE. The complete query below first creates the CTE, and then returns all of the IDs from it.

You could do this without a CTE, but if this were the first part of a very long query, removing the CTE would make it much harder to follow.
Also, it's important to note that CTEs only exist inside the query where you create them, and you can't reference them in later queries. So, any query that uses a CTE is always broken into two parts: (1) first, we create the CTE, and then (2) we write a query that uses the CTE.
Example: How many Bitcoin transactions are made per month?¶
We're going to use a CTE to find out how many Bitcoin transactions were made each day for the entire timespan of a bitcoin transaction dataset.
We'll investigate the transactions table. Here is a view of the first few rows. (The corresponding code is hidden, but you can un-hide it by clicking on the "Code" button below.)
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "crypto_bitcoin" dataset
dataset_ref = client.dataset("crypto_bitcoin", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "transactions" table
table_ref = dataset_ref.table("transactions")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the "transactions" table
client.list_rows(table, max_results=5).to_dataframe()
Using Kaggle's public dataset BigQuery integration.
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:19: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| hash | size | virtual_size | version | lock_time | block_hash | block_number | block_timestamp | block_timestamp_month | input_count | output_count | input_value | output_value | is_coinbase | fee | inputs | outputs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | f5d9499fb93c104c30f2f0a6055787c4e788b0fec8be89... | 512 | 512 | 1 | 0 | 000000000000000160f3b852402569f6a1f1b38cd1a35a... | 273029 | 2013-12-04 13:32:16+00:00 | 2013-12-01 | 2 | 6 | 978848094.000000000 | 978798000.000000000 | False | 50094.000000000 | [{'index': 0, 'spent_transaction_hash': '0608f... | [{'index': 0, 'script_asm': 'OP_DUP OP_HASH160... |
| 1 | de43728cb2982ab848938d061f55d522e15fe79bb5c3ab... | 512 | 512 | 1 | 0 | 00000000000000003a1260f6a07fa8a9f66bbc89972641... | 273014 | 2013-12-04 11:08:18+00:00 | 2013-12-01 | 2 | 6 | 633984346.000000000 | 633934346.000000000 | False | 50000.000000000 | [{'index': 0, 'spent_transaction_hash': '10e0e... | [{'index': 0, 'script_asm': 'OP_DUP OP_HASH160... |
| 2 | b9aaa4ab930570f8af4eda306637b9a96b6a5a8bba0b15... | 768 | 768 | 1 | 0 | 0000000000000003696f88dc5eb21e54f25d94938ad562... | 277416 | 2013-12-28 14:48:01+00:00 | 2013-12-01 | 4 | 1 | 170617369.000000000 | 170607369.000000000 | False | 10000.000000000 | [{'index': 0, 'spent_transaction_hash': '91ded... | [{'index': 0, 'script_asm': 'OP_DUP OP_HASH160... |
| 3 | 71863169438b978b5cc812261781a333a2a20b03509601... | 768 | 768 | 1 | 0 | 000000000000000356bdf67fc717f56f065935ec29edd0... | 272883 | 2013-12-03 18:47:25+00:00 | 2013-12-01 | 4 | 2 | 76686838.000000000 | 76586838.000000000 | False | 100000.000000000 | [{'index': 0, 'spent_transaction_hash': 'f9b6b... | [{'index': 0, 'script_asm': 'OP_DUP OP_HASH160... |
| 4 | eef7f497635bd52bf89393aff898bef8a93dce7058c9ee... | 768 | 768 | 1 | 0 | 000000000000000574f53b20f90356afb560c8e68587f7... | 272702 | 2013-12-02 19:11:15+00:00 | 2013-12-01 | 4 | 4 | 65856646.000000000 | 65816646.000000000 | False | 40000.000000000 | [{'index': 0, 'spent_transaction_hash': '54f5d... | [{'index': 0, 'script_asm': 'OP_DUP OP_HASH160... |
Since the block_timestamp column contains the date of each transaction in DATETIME format, we'll convert these into DATE format using the DATE() command.
We do that using a CTE, and then the next part of the query counts the number of transactions for each date and sorts the table so that earlier dates appear first.
# Query to select the number of transactions per date, sorted by date
query_with_CTE = """
WITH time AS
(
SELECT DATE(block_timestamp) AS trans_date
FROM `bigquery-public-data.crypto_bitcoin.transactions`
)
SELECT COUNT(1) AS transactions,
trans_date
FROM time
GROUP BY trans_date
ORDER BY trans_date
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query_with_CTE, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
transactions_by_date = query_job.to_dataframe()
# Print the first five rows
transactions_by_date.head()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
| transactions | trans_date | |
|---|---|---|
| 0 | 1 | 2009-01-03 |
| 1 | 14 | 2009-01-09 |
| 2 | 61 | 2009-01-10 |
| 3 | 93 | 2009-01-11 |
| 4 | 101 | 2009-01-12 |
Since they're returned sorted, we can easily plot the raw results to show us the number of Bitcoin transactions per day over the whole timespan of this dataset.
transactions_by_date.set_index('trans_date').plot()
<AxesSubplot:xlabel='trans_date'>

As you can see, common table expressions (CTEs) let you shift a lot of your data cleaning into SQL. That's an especially good thing in the case of BigQuery, because it is vastly faster than doing the work in Pandas.
Your turn¶
You now have the tools to stay organized even when writing more complex queries. Now use them here.
Have questions or comments? Visit the course discussion forum to chat with other learners.