
Joining Data¶
Introduction¶
You have the tools to obtain data from a single table in whatever format you want it. But what if the data you want is spread across multiple tables?
That's where JOIN comes in! JOIN is incredibly important in practical SQL workflows. So let's get started.
Example¶
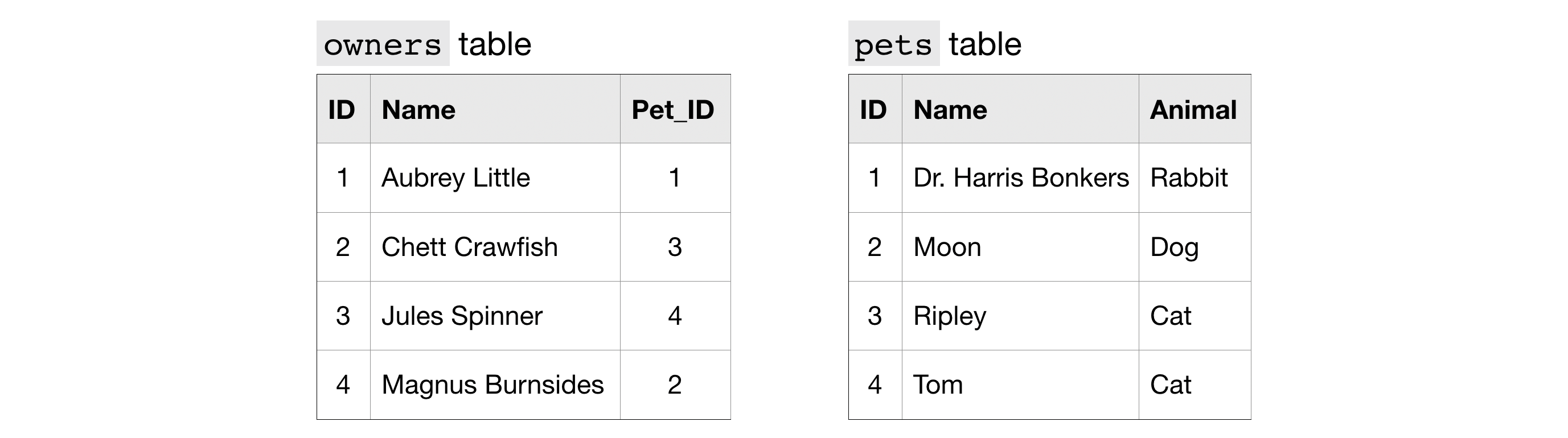
We'll use our imaginary pets table, which has three columns:
ID- ID number for the petName- name of the petAnimal- type of animal
We'll also add another table, called owners. This table also has three columns:
ID- ID number for the owner (different from the ID number for the pet)Name- name of the ownerPet_ID- ID number for the pet that belongs to the owner (which matches the ID number for the pet in thepetstable)
To get information that applies to a certain pet, we match the ID column in the pets table to the Pet_ID column in the owners table.
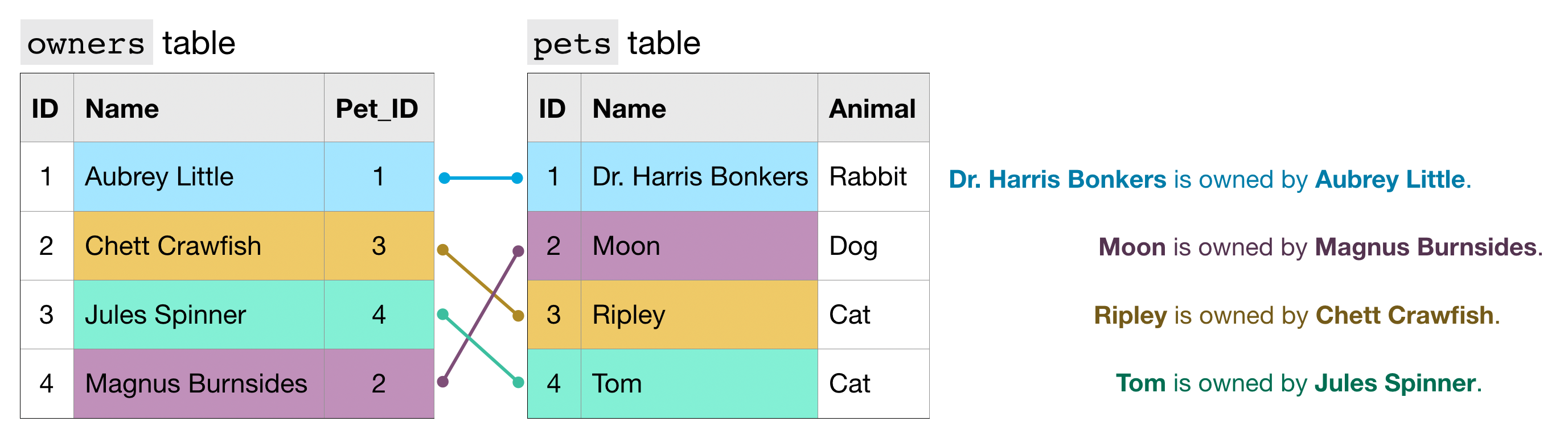
For example,
- the
petstable shows that Dr. Harris Bonkers is the pet with ID 1. - The
ownerstable shows that Aubrey Little is the owner of the pet with ID 1.
Putting these two facts together, Dr. Harris Bonkers is owned by Aubrey Little.
Fortunately, we don't have to do this by hand to figure out which owner goes with which pet. In the next section, you'll learn how to use JOIN to create a new table combining information from the pets and owners tables.
JOIN¶
Using JOIN, we can write a query to create a table with just two columns: the name of the pet and the name of the owner.

We combine information from both tables by matching rows where the ID column in the pets table matches the Pet_ID column in the owners table.
In the query, ON determines which column in each table to use to combine the tables. Notice that since the ID column exists in both tables, we have to clarify which one to use. We use p.ID to refer to the ID column from the pets table, and o.Pet_ID refers to the Pet_ID column from the owners table.
In general, when you're joining tables, it's a good habit to specify which table each of your columns comes from. That way, you don't have to pull up the schema every time you go back to read the query.
The type of JOIN we're using today is called an INNER JOIN. That means that a row will only be put in the final output table if the value in the columns you're using to combine them shows up in both the tables you're joining. For example, if Tom's ID number of 4 didn't exist in the pets table, we would only get 3 rows back from this query. There are other types of JOIN, but an INNER JOIN is very widely used, so it's a good one to start with.
Example: How many files are covered by each type of software license?¶
GitHub is the most popular place to collaborate on software projects. A GitHub repository (or repo) is a collection of files associated with a specific project.
Most repos on GitHub are shared under a specific legal license, which determines the legal restrictions on how they are used. For our example, we're going to look at how many different files have been released under each license.
We'll work with two tables in the database. The first table is the licenses table, which provides the name of each GitHub repo (in the repo_name column) and its corresponding license. Here's a view of the first five rows.
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "github_repos" dataset
dataset_ref = client.dataset("github_repos", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "licenses" table
licenses_ref = dataset_ref.table("licenses")
# API request - fetch the table
licenses_table = client.get_table(licenses_ref)
# Preview the first five lines of the "licenses" table
client.list_rows(licenses_table, max_results=5).to_dataframe()
Using Kaggle's public dataset BigQuery integration.
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:19: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| repo_name | license | |
|---|---|---|
| 0 | zoffixznet/perl6-App-Nopaste | artistic-2.0 |
| 1 | vikt0rs/devstack-plugin-zmq | artistic-2.0 |
| 2 | LegitTalon/nicolas | artistic-2.0 |
| 3 | Arabidopsis-Information-Portal/Intern-Hello-World | artistic-2.0 |
| 4 | andrewdonkin/falcon | artistic-2.0 |
The second table is the sample_files table, which provides, among other information, the GitHub repo that each file belongs to (in the repo_name column). The first several rows of this table are printed below.
# Construct a reference to the "sample_files" table
files_ref = dataset_ref.table("sample_files")
# API request - fetch the table
files_table = client.get_table(files_ref)
# Preview the first five lines of the "sample_files" table
client.list_rows(files_table, max_results=5).to_dataframe()
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:8: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint.
| repo_name | ref | path | mode | id | symlink_target | |
|---|---|---|---|---|---|---|
| 0 | git/git | refs/heads/master | RelNotes | 40960 | 62615ffa4e97803da96aefbc798ab50f949a8db7 | Documentation/RelNotes/2.10.0.txt |
| 1 | np/ling | refs/heads/master | tests/success/plug_compose.t/plug_compose.ll | 40960 | 0c1605e4b447158085656487dc477f7670c4bac1 | ../../../fixtures/all/plug_compose.ll |
| 2 | np/ling | refs/heads/master | fixtures/strict-par-success/parallel_assoc_lef... | 40960 | b59bff84ec03d12fabd3b51a27ed7e39a180097e | ../all/parallel_assoc_left.ll |
| 3 | np/ling | refs/heads/master | fixtures/sequence/parallel_assoc_2tensor2_left.ll | 40960 | f29523e3fb65702d99478e429eac6f801f32152b | ../all/parallel_assoc_2tensor2_left.ll |
| 4 | np/ling | refs/heads/master | fixtures/success/my_dual.ll | 40960 | 38a3af095088f90dfc956cb990e893909c3ab286 | ../all/my_dual.ll |
Next, we write a query that uses information in both tables to determine how many files are released in each license.
# Query to determine the number of files per license, sorted by number of files
query = """
SELECT L.license, COUNT(1) AS number_of_files
FROM `bigquery-public-data.github_repos.sample_files` AS sf
INNER JOIN `bigquery-public-data.github_repos.licenses` AS L
ON sf.repo_name = L.repo_name
GROUP BY L.license
ORDER BY number_of_files DESC
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
file_count_by_license = query_job.to_dataframe()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
It's a big query, and so we'll investigate each piece separately.

We'll begin with the JOIN (highlighted in blue above). This specifies the sources of data and how to join them. We use ON to specify that we combine the tables by matching the values in the repo_name columns in the tables.
Next, we'll talk about SELECT and GROUP BY (highlighted in yellow). The GROUP BY breaks the data into a different group for each license, before we COUNT the number of rows in the sample_files table that corresponds to each license. (Remember that you can count the number of rows with COUNT(1).)
Finally, the ORDER BY (highlighted in purple) sorts the results so that licenses with more files appear first.
It was a big query, but it gave us a nice table summarizing how many files have been committed under each license:
# Print the DataFrame
file_count_by_license
| license | number_of_files | |
|---|---|---|
| 0 | mit | 20418035 |
| 1 | gpl-2.0 | 16792944 |
| 2 | apache-2.0 | 7106098 |
| 3 | gpl-3.0 | 4902118 |
| 4 | bsd-3-clause | 2929339 |
| 5 | agpl-3.0 | 1292022 |
| 6 | lgpl-2.1 | 792881 |
| 7 | bsd-2-clause | 694532 |
| 8 | lgpl-3.0 | 563605 |
| 9 | mpl-2.0 | 472843 |
| 10 | cc0-1.0 | 405920 |
| 11 | epl-1.0 | 320146 |
| 12 | unlicense | 208872 |
| 13 | artistic-2.0 | 148414 |
| 14 | isc | 117503 |
You'll use JOIN clauses a lot and get very efficient with them as you get some practice.
Your turn¶
You are on the last step. Finish it by solving these exercises.
Have questions or comments? Visit the course discussion forum to chat with other learners.