
Nested and Repeated Data¶
Introduction¶
So far, you've worked with many types of data, including numeric types (integers, floating point values), strings, and the DATETIME type. In this tutorial, you'll learn how to query nested and repeated data. These are the most complex data types that you can find in BigQuery datasets!
Nested data¶
Consider a hypothetical dataset containing information about pets and their toys. We could organize this information in two different tables (a pets table and a toys table). The toys table could contain a "Pet_ID" column that could be used to match each toy to the pet that owns it.
Another option in BigQuery is to organize all of the information in a single table, similar to the pets_and_toys table below.

In this case, all of the information from the toys table is collapsed into a single column (the "Toy" column in the pets_and_toys table). We refer to the "Toy" column in the pets_and_toys table as a nested column, and say that the "Name" and "Type" fields are nested inside of it.
Nested columns have type STRUCT (or type RECORD). This is reflected in the table schema below.
Recall that we refer to the structure of a table as its schema. If you need to review how to interpret table schema, feel free to check out this lesson from the Intro to SQL micro-course.

To query a column with nested data, we need to identify each field in the context of the column that contains it:
Toy.Namerefers to the "Name" field in the "Toy" column, andToy.Typerefers to the "Type" field in the "Toy" column.

Otherwise, our usual rules remain the same - we need not change anything else about our queries.
Repeated data¶
Now consider the (more realistic!) case where each pet can have multiple toys. In this case, to collapse this information into a single table, we need to leverage a different datatype.
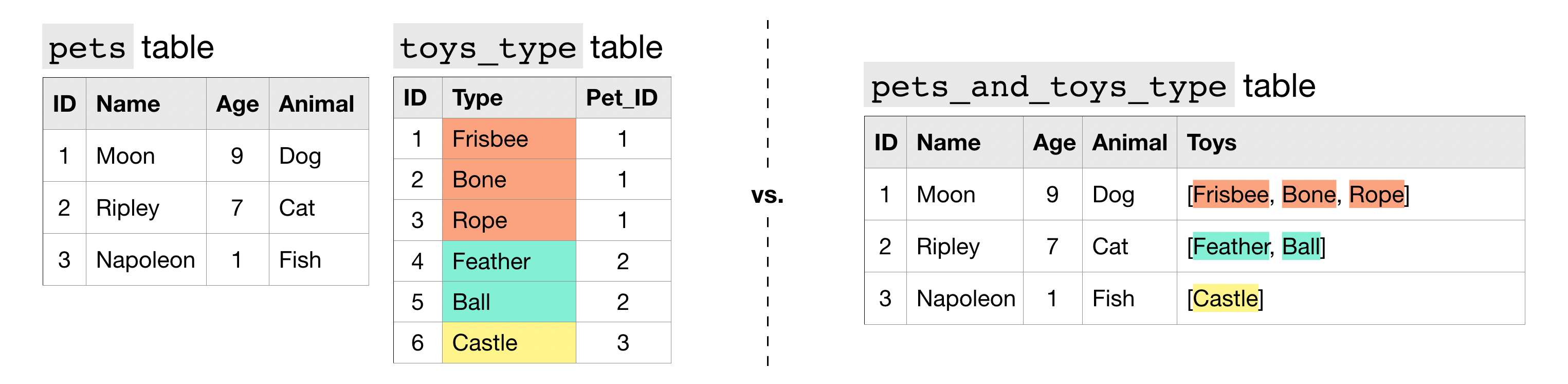
We say that the "Toys" column contains repeated data, because it permits more than one value for each row. This is reflected in the table schema below, where the mode of the "Toys" column appears as 'REPEATED'.

Each entry in a repeated field is an ARRAY, or an ordered list of (zero or more) values with the same datatype. For instance, the entry in the "Toys" column for Moon the Dog is [Frisbee, Bone, Rope], which is an ARRAY with three values.
When querying repeated data, we need to put the name of the column containing the repeated data inside an UNNEST() function.

This essentially flattens the repeated data (which is then appended to the right side of the table) so that we have one element on each row. For an illustration of this, check out the image below.
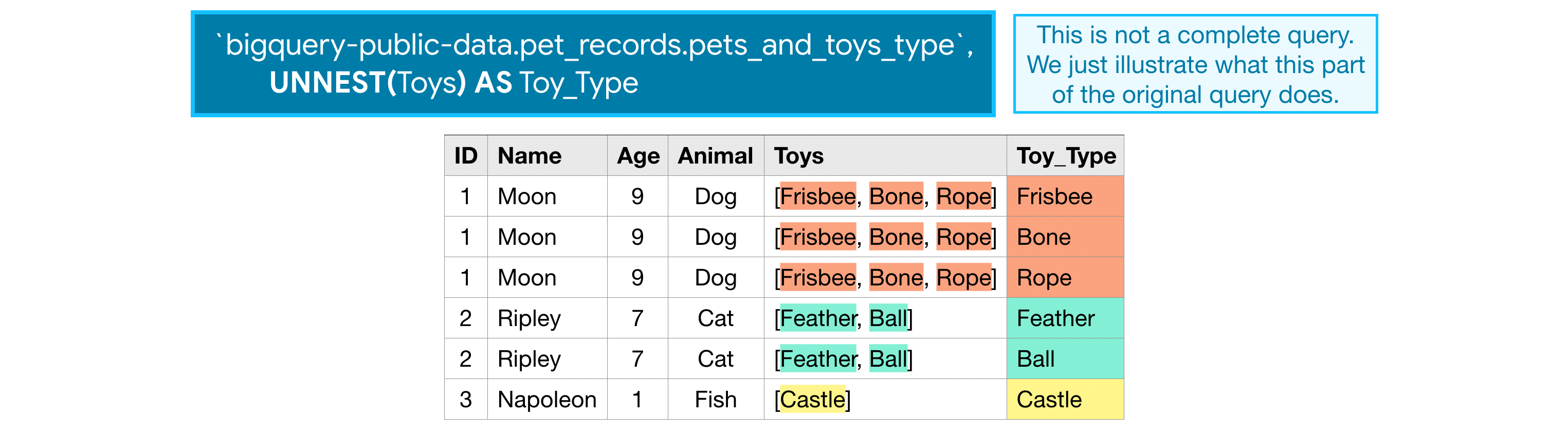
Nested and repeated data¶
Now, what if pets can have multiple toys, and we'd like to keep track of both the name and type of each toy? In this case, we can make the "Toys" column both nested and repeated.
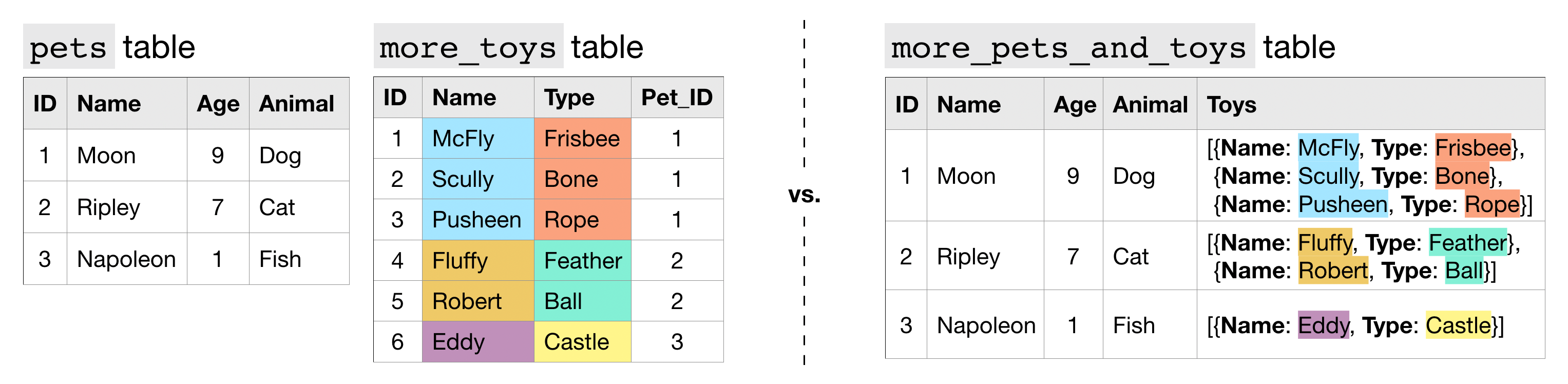
In the more_pets_and_toys table above, "Name" and "Type" are both fields contained within the "Toys" STRUCT, and each entry in both "Toys.Name" and "Toys.Type" is an ARRAY.
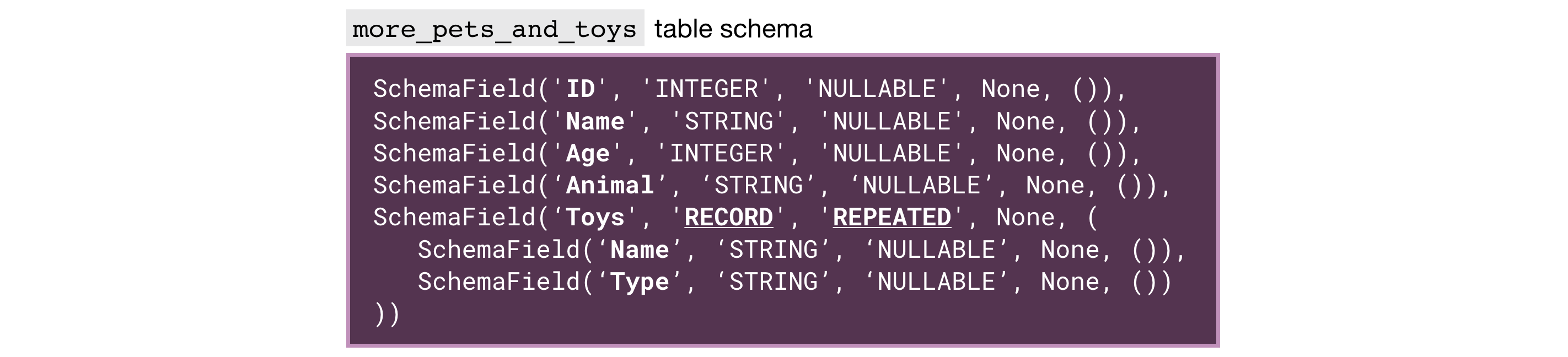
Let's look at a sample query.

Since the "Toys" column is repeated, we flatten it with the UNNEST() function. And, since we give the flattened column an alias of t, we can refer to the "Name" and "Type" fields in the "Toys" column as t.Name and t.Type, respectively.
To reinforce what you've learned, we'll apply these ideas to a real dataset in the section below.
Example¶
We'll work with the Google Analytics Sample dataset. It contains information tracking the behavior of visitors to the Google Merchandise store, an e-commerce website that sells Google branded items.
We begin by printing the first few rows of the ga_sessions_20170801 table. (We have hidden the corresponding code. To take a peek, click on the "Code" button below.) This table tracks visits to the website on August 1, 2017.
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "google_analytics_sample" dataset
dataset_ref = client.dataset("google_analytics_sample", project="bigquery-public-data")
# Construct a reference to the "ga_sessions_20170801" table
table_ref = dataset_ref.table("ga_sessions_20170801")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()
Using Kaggle's public dataset BigQuery integration.
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:16: UserWarning: Cannot use bqstorage_client if max_results is set, reverting to fetching data with the tabledata.list endpoint. app.launch_new_instance()
| visitorId | visitNumber | visitId | visitStartTime | date | totals | trafficSource | device | geoNetwork | customDimensions | hits | fullVisitorId | userId | clientId | channelGrouping | socialEngagementType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 1 | 1501583974 | 1501583974 | 20170801 | {'visits': 1, 'hits': 1, 'pageviews': 1, 'time... | {'referralPath': None, 'campaign': '(not set)'... | {'browser': 'Chrome', 'browserVersion': 'not a... | {'continent': 'Americas', 'subContinent': 'Car... | [] | [{'hitNumber': 1, 'time': 0, 'hour': 3, 'minut... | 2248281639583218707 | None | None | Organic Search | Not Socially Engaged |
| 1 | NaN | 1 | 1501616585 | 1501616585 | 20170801 | {'visits': 1, 'hits': 1, 'pageviews': 1, 'time... | {'referralPath': None, 'campaign': '(not set)'... | {'browser': 'Chrome', 'browserVersion': 'not a... | {'continent': 'Americas', 'subContinent': 'Nor... | [{'index': 4, 'value': 'North America'}] | [{'hitNumber': 1, 'time': 0, 'hour': 12, 'minu... | 8647436381089107732 | None | None | Organic Search | Not Socially Engaged |
| 2 | NaN | 1 | 1501583344 | 1501583344 | 20170801 | {'visits': 1, 'hits': 1, 'pageviews': 1, 'time... | {'referralPath': None, 'campaign': '(not set)'... | {'browser': 'Chrome', 'browserVersion': 'not a... | {'continent': 'Asia', 'subContinent': 'Souther... | [{'index': 4, 'value': 'APAC'}] | [{'hitNumber': 1, 'time': 0, 'hour': 3, 'minut... | 2055839700856389632 | None | None | Organic Search | Not Socially Engaged |
| 3 | NaN | 1 | 1501573386 | 1501573386 | 20170801 | {'visits': 1, 'hits': 1, 'pageviews': 1, 'time... | {'referralPath': None, 'campaign': '(not set)'... | {'browser': 'Chrome', 'browserVersion': 'not a... | {'continent': 'Europe', 'subContinent': 'Weste... | [{'index': 4, 'value': 'EMEA'}] | [{'hitNumber': 1, 'time': 0, 'hour': 0, 'minut... | 0750846065342433129 | None | None | Direct | Not Socially Engaged |
| 4 | NaN | 8 | 1501651467 | 1501651467 | 20170801 | {'visits': 1, 'hits': 1, 'pageviews': 1, 'time... | {'referralPath': None, 'campaign': '(not set)'... | {'browser': 'Chrome', 'browserVersion': 'not a... | {'continent': 'Americas', 'subContinent': 'Nor... | [{'index': 4, 'value': 'North America'}] | [{'hitNumber': 1, 'time': 0, 'hour': 22, 'minu... | 0573427169410921198 | None | None | Organic Search | Not Socially Engaged |
For a description of each field, refer to this data dictionary.
The table has many nested fields, which you can verify by looking at either the data dictionary (hint: search for appearances of 'RECORD' on the page) or the table preview above.
In our first query against this table, we'll work with the "totals" and "device" columns.
print("SCHEMA field for the 'totals' column:\n")
print(table.schema[5])
print("\nSCHEMA field for the 'device' column:\n")
print(table.schema[7])
SCHEMA field for the 'totals' column:
SchemaField('totals', 'RECORD', 'NULLABLE', None, (SchemaField('visits', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('hits', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('pageviews', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('timeOnSite', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('bounces', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('transactions', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('transactionRevenue', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('newVisits', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('screenviews', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('uniqueScreenviews', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('timeOnScreen', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('totalTransactionRevenue', 'INTEGER', 'NULLABLE', None, (), None), SchemaField('sessionQualityDim', 'INTEGER', 'NULLABLE', None, (), None)), None)
SCHEMA field for the 'device' column:
SchemaField('device', 'RECORD', 'NULLABLE', None, (SchemaField('browser', 'STRING', 'NULLABLE', None, (), None), SchemaField('browserVersion', 'STRING', 'NULLABLE', None, (), None), SchemaField('browserSize', 'STRING', 'NULLABLE', None, (), None), SchemaField('operatingSystem', 'STRING', 'NULLABLE', None, (), None), SchemaField('operatingSystemVersion', 'STRING', 'NULLABLE', None, (), None), SchemaField('isMobile', 'BOOLEAN', 'NULLABLE', None, (), None), SchemaField('mobileDeviceBranding', 'STRING', 'NULLABLE', None, (), None), SchemaField('mobileDeviceModel', 'STRING', 'NULLABLE', None, (), None), SchemaField('mobileInputSelector', 'STRING', 'NULLABLE', None, (), None), SchemaField('mobileDeviceInfo', 'STRING', 'NULLABLE', None, (), None), SchemaField('mobileDeviceMarketingName', 'STRING', 'NULLABLE', None, (), None), SchemaField('flashVersion', 'STRING', 'NULLABLE', None, (), None), SchemaField('javaEnabled', 'BOOLEAN', 'NULLABLE', None, (), None), SchemaField('language', 'STRING', 'NULLABLE', None, (), None), SchemaField('screenColors', 'STRING', 'NULLABLE', None, (), None), SchemaField('screenResolution', 'STRING', 'NULLABLE', None, (), None), SchemaField('deviceCategory', 'STRING', 'NULLABLE', None, (), None)), None)
We refer to the "browser" field (which is nested in the "device" column) and the "transactions" field (which is nested inside the "totals" column) as device.browser and totals.transactions in the query below:
# Query to count the number of transactions per browser
query = """
SELECT device.browser AS device_browser,
SUM(totals.transactions) as total_transactions
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
GROUP BY device_browser
ORDER BY total_transactions DESC
"""
# Run the query, and return a pandas DataFrame
result = client.query(query).result().to_dataframe()
result.head()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
| device_browser | total_transactions | |
|---|---|---|
| 0 | Chrome | 41.0 |
| 1 | Safari | 3.0 |
| 2 | Firefox | 1.0 |
| 3 | Internet Explorer | NaN |
| 4 | UC Browser | NaN |
By storing the information in the "device" and "totals" columns as STRUCTs (as opposed to separate tables), we avoid expensive JOINs. This increases performance and keeps us from having to worry about JOIN keys (and which tables have the exact data we need).
Now we'll work with the "hits" column as an example of data that is both nested and repeated. Since:
- "hits" is a STRUCT (contains nested data) and is repeated,
- "hitNumber", "page", and "type" are all nested inside the "hits" column, and
- "pagePath" is nested inside the "page" field,
we can query these fields with the following syntax:
# Query to determine most popular landing point on the website
query = """
SELECT hits.page.pagePath as path,
COUNT(hits.page.pagePath) as counts
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`,
UNNEST(hits) as hits
WHERE hits.type="PAGE" and hits.hitNumber=1
GROUP BY path
ORDER BY counts DESC
"""
# Run the query, and return a pandas DataFrame
result = client.query(query).result().to_dataframe()
result.head()
/opt/conda/lib/python3.7/site-packages/google/cloud/bigquery/client.py:440: UserWarning: Cannot create BigQuery Storage client, the dependency google-cloud-bigquery-storage is not installed. "Cannot create BigQuery Storage client, the dependency "
| path | counts | |
|---|---|---|
| 0 | /home | 1257 |
| 1 | /google+redesign/shop+by+brand/youtube | 587 |
| 2 | /google+redesign/apparel/mens/mens+t+shirts | 117 |
| 3 | /signin.html | 78 |
| 4 | /basket.html | 35 |
In this case, most users land on the website through the "/home" page.
Your turn¶
Use what you've learned to query complex datatypes in a real-world dataset.
Have questions or comments? Visit the course discussion forum to chat with other learners.