Esta semana revisaremos datos del Índice de Libertad de Prensa que confecciona cada año la asociación de Reporteros Sin Fronteras.
Diccionario de datos¶
| Variable | Clase | Descripción |
|---|---|---|
| codigo_iso | caracter | Código ISO del país |
| pais | caracter | País |
| anio | entero | Año del resultado |
| indice | entero | Puntaje Índice Libertad de Prensa (menor puntaje = mayor libertad de prensa) |
| ranking | entero | Ranking Libertad de Prensa |
Fuente original y adaptación¶
Los datos fueron extraídos de The World Bank. La fuente original es Reporteros sin Fronteras.
Por otro lado, estos archivos han sido modificado intencionalmente para ocupar todo lo aprendido en clases. A continuación, una breve descripción de cada uno de los data frames:
- libertad_prensa_codigo.csv: contiene la información codigo_iso/pais. Existe un código que tiene dos valores.
- libertad_prensa_01.csv: contiene la información pais/anio/indice/ranking (parte_01). Los nombres de las columnas estan en mayúscula.
- libertad_prensa_02.csv: contiene la información pais/anio/indice/ranking (parte_02). Los nombres de las columnas estan en mayúscula.
In [1]:
Copied!
import numpy as np
import pandas as pd
from os import listdir
from os.path import isfile, join
import numpy as np
import pandas as pd
from os import listdir
from os.path import isfile, join
In [2]:
Copied!
# codigo
path_codigo = "https://raw.githubusercontent.com/fralfaro/python_data_manipulation/main/docs/pandas/data/libertad_prensa_codigo.csv"
df_codigos = pd.read_csv(path_codigo)
df_codigos.head()
# codigo
path_codigo = "https://raw.githubusercontent.com/fralfaro/python_data_manipulation/main/docs/pandas/data/libertad_prensa_codigo.csv"
df_codigos = pd.read_csv(path_codigo)
df_codigos.head()
Out[2]:
| codigo_iso | pais | |
|---|---|---|
| 0 | AFG | Afghanistán |
| 1 | AGO | Angola |
| 2 | ALB | Albania |
| 3 | AND | Andorra |
| 4 | ARE | Emiratos Árabes Unidos |
In [3]:
Copied!
# libertad de prensa 01
path_codigo = "https://raw.githubusercontent.com/fralfaro/python_data_manipulation/main/docs/pandas/data/"
df_anio1 = pd.read_csv(path_codigo+"libertad_prensa_01.csv")
df_anio1.head()
# libertad de prensa 01
path_codigo = "https://raw.githubusercontent.com/fralfaro/python_data_manipulation/main/docs/pandas/data/"
df_anio1 = pd.read_csv(path_codigo+"libertad_prensa_01.csv")
df_anio1.head()
Out[3]:
| codigo_iso | anio | indice | ranking | |
|---|---|---|---|---|
| 0 | AFG | 2001 | 35.5 | 59.0 |
| 1 | AGO | 2001 | 30.2 | 50.0 |
| 2 | ALB | 2001 | NaN | NaN |
| 3 | AND | 2001 | NaN | NaN |
| 4 | ARE | 2001 | NaN | NaN |
In [4]:
Copied!
# libertad de prensa 02
df_anio2 = pd.read_csv(path_codigo+"libertad_prensa_02.csv")
df_anio2.head()
# libertad de prensa 02
df_anio2 = pd.read_csv(path_codigo+"libertad_prensa_02.csv")
df_anio2.head()
Out[4]:
| codigo_iso | anio | indice | ranking | |
|---|---|---|---|---|
| 0 | AFG | 2012 | 37.36 | 112.0 |
| 1 | AGO | 2012 | 37.80 | 114.0 |
| 2 | ALB | 2012 | 30.88 | 87.0 |
| 3 | AND | 2012 | 6.82 | 152.0 |
| 4 | ARE | 2012 | 33.49 | 98.0 |
El objetivo es tratar de obtener la mayor información posible de este conjunto de datos. Para cumplir este objetivo debe resolver las siguientes problemáticas:
- Lo primero será juntar toda la información en un solo archivo, para ello necesitamos seguir los siguientes pasos:
- a) Crear el archivo df_anio, que contenga la información de libertad_prensa_01.csv y libertad_prensa_02.csv. Luego, normalice el nombre de las columnas a minúscula.
- b) Encuentre y elimine el dato que esta duplicado en el archivo df_codigo.
- c) Crear el archivo df que junte la información del archivo df_anio con df_codigo por la columna codigo_iso.
Hint: Para juntar por anio ocupe la función pd.concat. Para juntar información por columna ocupe pd.merge.
In [5]:
Copied!
# creamos el dataframe con la información de todos los años
df_anio = pd.concat([df_anio1,df_anio2])
# cambiamos los nombres de las columnas de df_anio a minúsculas
df_anio.columns = df_anio.columns.str.lower()
# imprimir resultados
df_anio.head()
# creamos el dataframe con la información de todos los años
df_anio = pd.concat([df_anio1,df_anio2])
# cambiamos los nombres de las columnas de df_anio a minúsculas
df_anio.columns = df_anio.columns.str.lower()
# imprimir resultados
df_anio.head()
Out[5]:
| codigo_iso | anio | indice | ranking | |
|---|---|---|---|---|
| 0 | AFG | 2001 | 35.5 | 59.0 |
| 1 | AGO | 2001 | 30.2 | 50.0 |
| 2 | ALB | 2001 | NaN | NaN |
| 3 | AND | 2001 | NaN | NaN |
| 4 | ARE | 2001 | NaN | NaN |
In [6]:
Copied!
# eliminamos el dato repetido en df_codigos
print("Total duplicados antes")
print(df_codigos["codigo_iso"].value_counts().loc[lambda x: x>1])
df_codigos = df_codigos.drop_duplicates('codigo_iso')
print("\nTotal duplicados despues")
print(df_codigos["codigo_iso"].value_counts().loc[lambda x: x>1])
# eliminamos el dato repetido en df_codigos
print("Total duplicados antes")
print(df_codigos["codigo_iso"].value_counts().loc[lambda x: x>1])
df_codigos = df_codigos.drop_duplicates('codigo_iso')
print("\nTotal duplicados despues")
print(df_codigos["codigo_iso"].value_counts().loc[lambda x: x>1])
Total duplicados antes ZWE 2 Name: codigo_iso, dtype: int64 Total duplicados despues Series([], Name: codigo_iso, dtype: int64)
In [7]:
Copied!
# juntar informacion
df = df_anio.merge(df_codigos,on = 'codigo_iso' )
df.head()
# juntar informacion
df = df_anio.merge(df_codigos,on = 'codigo_iso' )
df.head()
Out[7]:
| codigo_iso | anio | indice | ranking | pais | |
|---|---|---|---|---|---|
| 0 | AFG | 2001 | 35.50 | 59.0 | Afghanistán |
| 1 | AFG | 2002 | 40.17 | 78.0 | Afghanistán |
| 2 | AFG | 2003 | 28.25 | 49.0 | Afghanistán |
| 3 | AFG | 2004 | 39.17 | 62.0 | Afghanistán |
| 4 | AFG | 2005 | 44.25 | 67.0 | Afghanistán |
- Encontrar:
- ¿Cuál es el número de observaciones en el conjunto de datos?
- ¿Cuál es el número de columnas en el conjunto de datos?
- Imprime el nombre de todas las columnas
- ¿Cuál es el tipo de datos de cada columna?
- Describir el conjunto de datos (hint: .describe())
In [8]:
Copied!
# respuesta
(n_obs, n_cols) = df.shape
print(f"Hay {n_obs} observaciones en el conjunto de datos")
print(f"Hay {n_cols} columnas en el conjunto de datos")
# respuesta
(n_obs, n_cols) = df.shape
print(f"Hay {n_obs} observaciones en el conjunto de datos")
print(f"Hay {n_cols} columnas en el conjunto de datos")
Hay 3060 observaciones en el conjunto de datos Hay 5 columnas en el conjunto de datos
- Desarrolle una función
resumen_df(df)para encontrar el total de elementos distintos y vacíos por columnas.
In [9]:
Copied!
# respuesta
def resumen_df(df):
"""
funcion resumen con elementos
distintos y vacios por columnas
"""
nombres = df.columns
l1 = []
l2 = []
for nombre in nombres:
pd_series = df[nombre]
# elementos distintos
l_unique = pd_series.unique()
# elementos vacios
l_vacios = pd_series[pd_series.isna()]
l1.append(len(l_unique))
l2.append(len(l_vacios))
result = pd.DataFrame({'nombres': nombres})
result['elementos_distintos'] = l1
result['elementos_vacios'] = l2
return result
# respuesta
def resumen_df(df):
"""
funcion resumen con elementos
distintos y vacios por columnas
"""
nombres = df.columns
l1 = []
l2 = []
for nombre in nombres:
pd_series = df[nombre]
# elementos distintos
l_unique = pd_series.unique()
# elementos vacios
l_vacios = pd_series[pd_series.isna()]
l1.append(len(l_unique))
l2.append(len(l_vacios))
result = pd.DataFrame({'nombres': nombres})
result['elementos_distintos'] = l1
result['elementos_vacios'] = l2
return result
In [10]:
Copied!
# retornar
resumen_df(df)
# retornar
resumen_df(df)
Out[10]:
| nombres | elementos_distintos | elementos_vacios | |
|---|---|---|---|
| 0 | codigo_iso | 180 | 0 |
| 1 | anio | 17 | 0 |
| 2 | indice | 1551 | 396 |
| 3 | ranking | 194 | 223 |
| 4 | pais | 179 | 0 |
- Para los paises latinoamericano, encuentre por año el país con mayor y menor
indice.
- a) Mediante un ciclo for.
- b) Mediante un groupby.
In [11]:
Copied!
# respuesta
america = ['ARG', 'ATG', 'BLZ', 'BOL', 'BRA', 'CAN', 'CHL', 'COL', 'CRI',
'CUB', 'DOM', 'ECU', 'GRD', 'GTM', 'GUY', 'HND', 'HTI', 'JAM',
'MEX', 'NIC', 'PAN', 'PER', 'PRY', 'SLV', 'SUR', 'TTO', 'URY',
'USA', 'VEN']
df_america = df.loc[lambda x: x.codigo_iso.isin(america)]
# respuesta
america = ['ARG', 'ATG', 'BLZ', 'BOL', 'BRA', 'CAN', 'CHL', 'COL', 'CRI',
'CUB', 'DOM', 'ECU', 'GRD', 'GTM', 'GUY', 'HND', 'HTI', 'JAM',
'MEX', 'NIC', 'PAN', 'PER', 'PRY', 'SLV', 'SUR', 'TTO', 'URY',
'USA', 'VEN']
df_america = df.loc[lambda x: x.codigo_iso.isin(america)]
In [12]:
Copied!
# ciclo for
dct = dict()
for pais in america:
df_temp =df.loc[lambda x: x.codigo_iso == pais]
dct[pais] = (df_temp['indice'].max(),df_temp['indice'].min())
dct
# ciclo for
dct = dict()
for pais in america:
df_temp =df.loc[lambda x: x.codigo_iso == pais]
dct[pais] = (df_temp['indice'].max(),df_temp['indice'].min())
dct
Out[12]:
{'ARG': (35826.0, 11.33),
'ATG': (20.81, 20.81),
'BLZ': (27.5, 17.05),
'BOL': (35.38, 4.5),
'BRA': (34.03, 14.5),
'CAN': (16.53, 0.8),
'CHL': (26.24, 6.5),
'COL': (51.5, 35.5),
'CRI': (14.01, 3.83),
'CUB': (106.83, 63.81),
'DOM': (28.34, 6.75),
'ECU': (34.69, 5.5),
'GRD': (12.0, 12.0),
'GTM': (39.33, 16.5),
'GUY': (27.21, 10.5),
'HND': (51.13, 11.75),
'HTI': (42.13, 15.0),
'JAM': (12.73, 3.33),
'MEX': (53.63, 17.67),
'NIC': (35.53, 6.5),
'PAN': (32.95, 9.5),
'PER': (40.0, 9.5),
'PRY': (35.64, 7.17),
'SLV': (29.81, 5.75),
'SUR': (18.2, 6.0),
'TTO': (24.74, 1.0),
'URY': (17.43, 4.0),
'USA': (25.69, 4.0),
'VEN': (49.1, 23.0)}
In [13]:
Copied!
# ciclo groupby
df_america.groupby('codigo_iso')['indice'].agg({max,min})
# ciclo groupby
df_america.groupby('codigo_iso')['indice'].agg({max,min})
Out[13]:
| max | min | |
|---|---|---|
| codigo_iso | ||
| ARG | 35826.00 | 11.33 |
| ATG | 20.81 | 20.81 |
| BLZ | 27.50 | 17.05 |
| BOL | 35.38 | 4.50 |
| BRA | 34.03 | 14.50 |
| CAN | 16.53 | 0.80 |
| CHL | 26.24 | 6.50 |
| COL | 51.50 | 35.50 |
| CRI | 14.01 | 3.83 |
| CUB | 106.83 | 63.81 |
| DOM | 28.34 | 6.75 |
| ECU | 34.69 | 5.50 |
| GRD | 12.00 | 12.00 |
| GTM | 39.33 | 16.50 |
| GUY | 27.21 | 10.50 |
| HND | 51.13 | 11.75 |
| HTI | 42.13 | 15.00 |
| JAM | 12.73 | 3.33 |
| MEX | 53.63 | 17.67 |
| NIC | 35.53 | 6.50 |
| PAN | 32.95 | 9.50 |
| PER | 40.00 | 9.50 |
| PRY | 35.64 | 7.17 |
| SLV | 29.81 | 5.75 |
| SUR | 18.20 | 6.00 |
| TTO | 24.74 | 1.00 |
| URY | 17.43 | 4.00 |
| USA | 25.69 | 4.00 |
| VEN | 49.10 | 23.00 |
- Para cada país, muestre el indice máximo que alcanzo por anio. Para los datos nulos, rellene con el valor 0.
Ejemplo:
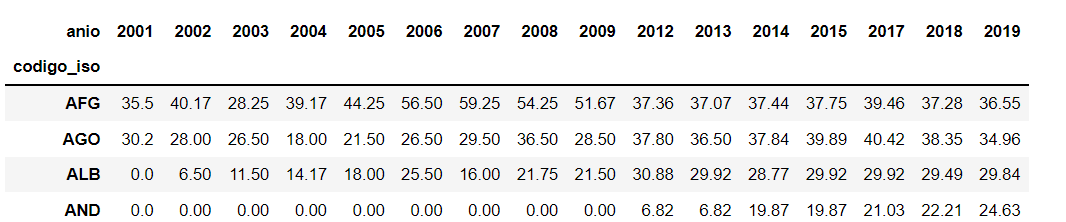
Hint: Utilice la función pd.pivot_table.
In [14]:
Copied!
df_pivot = df.pivot_table(
index="codigo_iso",
columns="anio",
values="indice",
fill_value=0
)
df_pivot
df_pivot = df.pivot_table(
index="codigo_iso",
columns="anio",
values="indice",
fill_value=0
)
df_pivot
Out[14]:
| anio | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2012 | 2013 | 2014 | 2015 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| codigo_iso | ||||||||||||||||
| AFG | 35.5 | 40.17 | 28.25 | 39.17 | 44.25 | 56.50 | 59.25 | 54.25 | 51.67 | 37.36 | 37.07 | 37.44 | 37.75 | 39.46 | 37.28 | 36.55 |
| AGO | 30.2 | 28.00 | 26.50 | 18.00 | 21.50 | 26.50 | 29.50 | 36.50 | 28.50 | 37.80 | 36.50 | 37.84 | 39.89 | 40.42 | 38.35 | 34.96 |
| ALB | 0.0 | 6.50 | 11.50 | 14.17 | 18.00 | 25.50 | 16.00 | 21.75 | 21.50 | 30.88 | 29.92 | 28.77 | 29.92 | 29.92 | 29.49 | 29.84 |
| AND | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 6.82 | 6.82 | 19.87 | 19.87 | 21.03 | 22.21 | 24.63 |
| ARE | 0.0 | 37.00 | 50.25 | 25.75 | 17.50 | 20.25 | 14.50 | 21.50 | 23.75 | 33.49 | 36.03 | 36.73 | 36.73 | 39.39 | 40.86 | 43.63 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| WSM | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 33.00 | 23.84 | 22.02 | 22.32 | 18.80 | 16.41 | 16.69 | 18.25 |
| YEM | 34.8 | 41.83 | 48.00 | 46.25 | 54.00 | 56.67 | 59.00 | 83.38 | 82.13 | 69.22 | 67.26 | 66.36 | 67.07 | 65.80 | 62.23 | 61.66 |
| ZAF | 7.5 | 3.33 | 5.00 | 6.50 | 11.25 | 13.00 | 8.00 | 8.50 | 12.00 | 24.56 | 23.19 | 22.06 | 21.92 | 20.12 | 20.39 | 22.19 |
| ZMB | 26.8 | 23.25 | 29.75 | 23.00 | 22.50 | 21.50 | 15.50 | 26.75 | 22.00 | 27.93 | 30.89 | 34.35 | 35.08 | 36.48 | 35.36 | 36.38 |
| ZWE | 48.3 | 45.50 | 67.50 | 64.25 | 50.00 | 62.00 | 54.00 | 46.50 | 39.50 | 38.12 | 39.19 | 39.19 | 40.41 | 41.44 | 40.53 | 42.23 |
180 rows × 16 columns