![]()
Indexación y Selección¶
Indexación pandas Series¶
La indexación y selección de objetos Series de Pandas es una de las funcionalidades más importantes de la biblioteca, y permite acceder a los elementos individuales de una serie, así como seleccionar subconjuntos de elementos según diferentes criterios.
Para acceder a los elementos hay 2 formas de hacerlo.
Por etiquetas o método
.locPor posición o el método
.iloc
import pandas as pd
data = {'manzanas': 10, 'naranjas': 5, 'plátanos': 7, 'peras': 3}
frutas = pd.Series(data)
frutas
manzanas 10 naranjas 5 plátanos 7 peras 3 dtype: int64
Indexación de etiquetas¶
Podemos acceder a los elementos de la serie utilizando las etiquetas del índice de la serie. Podemos acceder a los elementos por su etiqueta de la siguiente manera:
# acceder por indice 'manzana' - sin '.loc'
print(frutas['manzanas']) # 10
10
# acceder por indice 'manzana' - con '.loc'
print(frutas.loc['manzanas']) # 10
10
Indexación de posición¶
Podemos acceder a los elementos de la serie utilizando la posición en la serie. Podemos acceder a los elementos por su posición de la siguiente manera:
# acceder por la posicion 0 - sin '.loc'
print(frutas[0]) # 10
10
C:\Users\franc\AppData\Local\Temp\ipykernel_17048\1885408761.py:2: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]` print(frutas[0]) # 10
# acceder por la posicion 0 - con '.iloc'
print(frutas.iloc[0]) # 10
10
Nota: De aquí en más utilizaremos
.loce.ilocpara acceder a los elementos de un Dataframe, para ser explícito en la forma de acceder a los datos.
Selección de múltiples elementos¶
Podemos seleccionar múltiples elementos de la serie de varias maneras. Por ejemplo, podemos seleccionar los elementos por etiquetas de índice utilizando una lista de etiquetas:
# seleccionar por indices 'manzanas' y 'naranjas'
print(frutas.loc[['manzanas', 'naranjas']])
manzanas 10 naranjas 5 dtype: int64
También podemos seleccionar los elementos por su posición utilizando la función iloc():
# acceder por posicion 0 y 2
print(frutas.iloc[[0, 2]])
manzanas 10 plátanos 7 dtype: int64
Selección de rangos¶
Podemos seleccionar rangos de elementos de la serie de varias maneras. Podemos seleccionar un rango de elementos utilizando etiquetas de índice:
# rango de indices
print(frutas.loc['manzanas':'plátanos'])
manzanas 10 naranjas 5 plátanos 7 dtype: int64
También podemos seleccionar un rango de elementos utilizando la función iloc() y especificando las posiciones del rango:
# rango de posiciones
print(frutas.iloc[1:3])
naranjas 5 plátanos 7 dtype: int64
Indexación pandas dataframe¶
En Pandas, la indexación y selección de datos en un DataFrame se pueden realizar de varias maneras. Primero, es importante tener en cuenta que un DataFrame consta de filas y columnas etiquetadas. La selección de datos se puede hacer utilizando estas etiquetas o mediante la posición de las filas y columnas.
Aquí hay algunas formas comunes de indexación y selección de datos en un DataFrame de Pandas:
Selección de columnas¶
Podemos seleccionar una o varias columnas de un DataFrame de la siguiente manera:
# Crear un DataFrame de ejemplo
data = {
'nombre': ['Juan', 'Ana', 'Pedro'],
'edad': [28, 23, 35],
'ciudad': ['Madrid', 'Barcelona', 'Valencia'],
}
df = pd.DataFrame(data,index = ['a','b','c'])
df
| nombre | edad | ciudad | |
|---|---|---|---|
| a | Juan | 28 | Madrid |
| b | Ana | 23 | Barcelona |
| c | Pedro | 35 | Valencia |
# Selección de una columna
nombre_columna = df['nombre']
nombre_columna
a Juan b Ana c Pedro Name: nombre, dtype: object
# Selección de varias columnas
varias_columnas = df[['nombre', 'edad']]
varias_columnas
| nombre | edad | |
|---|---|---|
| a | Juan | 28 |
| b | Ana | 23 |
| c | Pedro | 35 |
Selección de filas¶
Podemos seleccionar una o varias filas de un DataFrame utilizando el índice de la fila o utilizando la función iloc():
# Selección de una fila por etiqueta
fila = df.loc['a']
fila
nombre Juan edad 28 ciudad Madrid Name: a, dtype: object
# Selección de varias filas por etiqueta
varias_filas = df.loc['a':'b']
varias_filas
| nombre | edad | ciudad | |
|---|---|---|---|
| a | Juan | 28 | Madrid |
| b | Ana | 23 | Barcelona |
# Selección de una fila por posición
fila_posicion = df.iloc[0]
fila_posicion
nombre Juan edad 28 ciudad Madrid Name: a, dtype: object
# Selección de varias filas por posición
varias_filas_posicion = df.iloc[0:2]
varias_filas_posicion
| nombre | edad | ciudad | |
|---|---|---|---|
| a | Juan | 28 | Madrid |
| b | Ana | 23 | Barcelona |
Selección de filas y columnas¶
Podemos seleccionar un subconjunto de filas y columnas de un DataFrame utilizando etiquetas o posición de fila y columna:
# Selección de filas y columnas por etiqueta
subconjunto = df.loc['a':'b', ['nombre', 'edad']]
subconjunto
| nombre | edad | |
|---|---|---|
| a | Juan | 28 |
| b | Ana | 23 |
# Selección de filas y columnas por posición
subconjunto_posicion = df.iloc[0:2, 0:2]
subconjunto_posicion
| nombre | edad | |
|---|---|---|
| a | Juan | 28 |
| b | Ana | 23 |
Diferencia de loc e iloc¶
loc e iloc son dos atributos que se utilizan para la selección de datos en un DataFrame o una Serie. Ambos atributos permiten la selección de filas y columnas específicas en un DataFrame, pero utilizan diferentes métodos para hacerlo.
loc: este atributo permite la selección de datos mediante etiquetas de filas y columnas. Se utiliza para acceder a las filas y columnas utilizando etiquetas explícitas. Por ejemplo,data.loc[3, 'columna']seleccionaría el valor en la fila 3 y la columna 'columna'.iloc: este atributo permite la selección de datos mediante índices enteros de filas y columnas. Se utiliza para acceder a las filas y columnas utilizando índices enteros implícitos. Por ejemplo,df.iloc[3, 1]seleccionaría el valor en la cuarta fila y la segunda columna.
La principal diferencia entre loc e iloc es el tipo de indexación utilizado. loc se utiliza para indexar los datos mediante etiquetas, mientras que iloc se utiliza para indexar los datos mediante la posición en la matriz de datos.
Además, loc es inclusivo en el sentido de que el límite superior se incluye en la selección, mientras que iloc es exclusivo en el límite superior y no incluye el valor correspondiente. Es decir, loc incluye la última fila/columna seleccionada, mientras que iloc no lo hace.
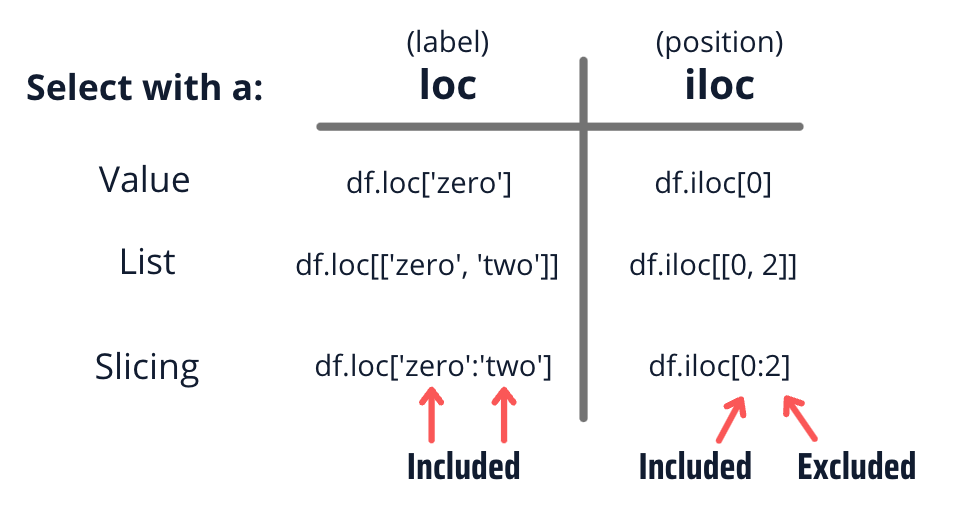
Por ejemplo, si tenemos un DataFrame con índice de etiquetas de A a E y un índice numérico de 0 a 4, la selección utilizando loc incluiría la última fila y columna seleccionada, mientras que la selección utilizando iloc no lo haría:
df = pd.DataFrame({
'col_1': [1, 2, 3, 4, 5],
'col_2': [6, 7, 8, 9, 10],
'col_3': [11, 12, 13, 14, 15]},
index=['A', 'B', 'C', 'D', 'E']
)
df
| col_1 | col_2 | col_3 | |
|---|---|---|---|
| A | 1 | 6 | 11 |
| B | 2 | 7 | 12 |
| C | 3 | 8 | 13 |
| D | 4 | 9 | 14 |
| E | 5 | 10 | 15 |
# Selección utilizando loc
df.loc['B':'D', ['col_1','col_2']]
| col_1 | col_2 | |
|---|---|---|
| B | 2 | 7 |
| C | 3 | 8 |
| D | 4 | 9 |
# Selección utilizando iloc
df.iloc[1:4, 0:2]
| col_1 | col_2 | |
|---|---|---|
| B | 2 | 7 |
| C | 3 | 8 |
| D | 4 | 9 |
En resumen, la principal diferencia entre loc e iloc es el tipo de indexación utilizado y cómo se maneja el límite superior en la selección. loc se utiliza para indexar los datos mediante etiquetas explícitas, mientras que iloc se utiliza para indexar los datos mediante posiciones implícitas.