![]()
Introducción¶
El Machine Learning (aprendizaje automático) es una rama de la inteligencia artificial que desarrolla algoritmos y modelos matemáticos para que las computadoras aprendan a realizar tareas a partir de datos, sin programación específica para cada tarea.
Este proceso implica entrenar un modelo con datos que le enseñan a reconocer patrones y relaciones. Una vez entrenado, el modelo puede aplicarse a nuevos datos para hacer predicciones o tomar decisiones.
El machine learning se utiliza en diversas aplicaciones, como análisis de datos, reconocimiento de voz, clasificación de imágenes y vehículos autónomos. En esencia, permite a las computadoras aprender y mejorar con la experiencia.
Modelos Matemáticos¶

Un modelo matemático es una representación de un sistema real mediante ecuaciones que relacionan sus variables, usado para describir y predecir su comportamiento.
Características:
- Se aplican en disciplinas como física, economía y biología.
- Su validez depende de pruebas y observaciones experimentales.
No es:
- Una réplica exacta de la realidad.
- Un sustituto de mediciones o experimentos.
Tipos de Problemas¶

El Machine Learning es una técnica que aborda diversos problemas en distintos campos y aplicaciones. Entre los principales tipos de problemas que puede resolver se incluyen:
- Aprendizaje supervisado
- Aprendizaje no supervisado
- Aprendizaje por refuerzo
Aprendizaje Supervisado¶
El aprendizaje supervisado es un enfoque en el que el sistema aprende a partir de datos etiquetados, es decir, datos en los que se conoce la respuesta correcta. El algoritmo analiza estos datos y genera una función que relaciona las entradas (características) con las salidas esperadas (etiquetas o valores).
- Ejemplo: La clasificación de correos electrónicos como spam o no spam. El algoritmo se entrena con un conjunto de correos previamente clasificados para identificar patrones y aplicarlos a nuevos correos.
- Aplicaciones: Reconocimiento de voz, predicción de precios, diagnósticos médicos, etc.
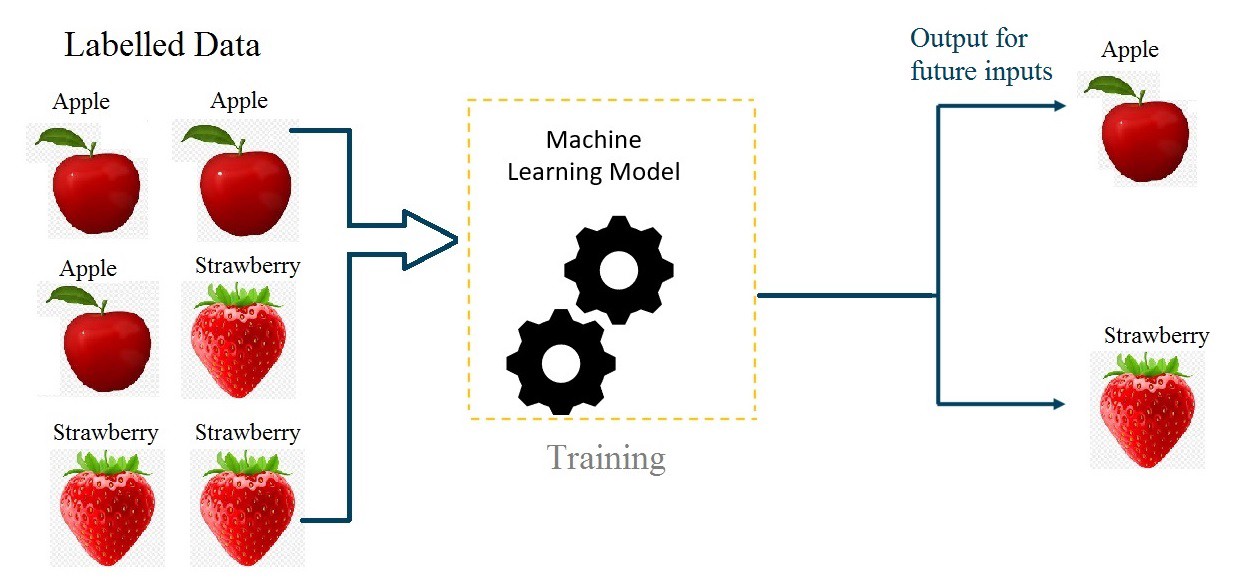
Aprendizaje No Supervisado¶
El aprendizaje no supervisado trabaja con datos que no han sido etiquetados previamente. El sistema debe identificar patrones, agrupaciones o estructuras ocultas dentro de los datos sin una respuesta específica proporcionada durante el entrenamiento.
- Ejemplo: Agrupar clientes en un mercado según sus hábitos de compra. El algoritmo analiza los datos y detecta grupos de comportamiento similares sin conocer de antemano a qué categoría pertenece cada cliente.
- Aplicaciones: Análisis de segmentación de clientes, reducción de dimensionalidad, detección de anomalías.

Aprendizaje por Refuerzo¶
El aprendizaje por refuerzo es un enfoque inspirado en la psicología conductista. Un agente aprende a tomar decisiones en un entorno para maximizar una "recompensa" acumulada. Se basa en la prueba y error, donde el agente recibe recompensas o castigos según las acciones que tome, lo que le permite mejorar su comportamiento a lo largo del tiempo.
- Ejemplo: Un agente de inteligencia artificial aprendiendo a jugar un videojuego. El agente recibe puntos (recompensas) por tomar acciones correctas y pierde puntos (castigos) por acciones incorrectas, refinando su estrategia con la experiencia.
- Aplicaciones: Conducción autónoma, robótica, sistemas de recomendación, optimización de procesos.

Algoritmos más Utilizados¶
![]()
Los algoritmos más comunes en Machine Learning incluyen:
Regresión Lineal: Método estadístico que modela la relación entre una variable dependiente y una o más variables independientes utilizando una línea recta. Es útil para predecir valores continuos, como precios o temperaturas.
Regresión Logística: Modelo utilizado para problemas de clasificación binaria (sí/no, verdadero/falso). Utiliza una función logística para predecir la probabilidad de que una entrada pertenezca a una de las dos clases.
Árboles de Decisión: Estructuras de datos que dividen iterativamente el conjunto de datos en subconjuntos basados en características específicas. Son útiles para problemas de clasificación y regresión, proporcionando interpretaciones claras de las decisiones.
Random Forest: Conjunto de árboles de decisión entrenados con diferentes subconjuntos del conjunto de datos. Combina las predicciones de múltiples árboles para mejorar la precisión y reducir el riesgo de sobreajuste.
SVM (Máquinas de Vectores de Soporte): Algoritmo de clasificación que busca encontrar el hiperplano que mejor separa las clases de datos. Es efectivo en espacios de alta dimensionalidad y cuando la separación entre clases no es lineal.
KNN (K-Vecinos más Cercanos): Algoritmo de clasificación que asigna una nueva instancia a la clase más común entre sus "K" vecinos más cercanos en el espacio de características. Es sencillo y útil para tareas de clasificación y regresión.
K-means: Algoritmo de agrupamiento (clustering) que divide un conjunto de datos en "K" grupos basándose en sus características. Asigna cada punto de datos al grupo con el centroide más cercano, minimizando la variación interna de los grupos.
¿Qué se Necesita para Aprender Machine Learning?¶
Álgebra Lineal: Base matemática que involucra vectores, matrices y operaciones lineales. Es fundamental para entender modelos, optimizar funciones y manejar datos.
Probabilidad y Estadística: Permite analizar y entender los datos, medir la incertidumbre y construir modelos predictivos.
Optimización: Proceso de encontrar los mejores parámetros para un modelo. Implica minimizar o maximizar funciones objetivo para mejorar el rendimiento de los algoritmos de Machine Learning.
Librerías de Machine Learning en Python¶
Python destaca por su comunidad activa y numerosas librerías para Machine Learning. Entre las más utilizadas se encuentran:
Scikit-Learn¶

Scikit-learn es la librería principal para Machine Learning en Python. Incluye implementaciones de algoritmos para clasificación, extracción de características, regresión, agrupamiento, reducción de dimensiones, selección de modelos y preprocesamiento.
Statsmodels¶

Statsmodels se enfoca en modelos estadísticos y se utiliza principalmente para análisis predictivos y exploratorios, ofreciendo amplias pruebas estadísticas para validar modelos.
Metodologías para Proyectos de Ciencia de Datos¶
Principales Metodologías¶
Existen diversas metodologías para proyectos de ciencia de datos, cada una con un enfoque particular. Las más destacadas incluyen:
CRISP-DM: Un proceso estándar para la minería de datos, estructurado en seis fases que guían el proyecto de principio a fin.
KDD: Se enfoca en la extracción de conocimiento a partir de grandes conjuntos de datos, siguiendo un proceso sistemático.
La elección de la metodología depende de los objetivos y requisitos específicos del proyecto. No obstante, un enfoque estructurado y sistemático siempre es fundamental para abordar todas las etapas del proceso de ciencia de datos.
Pasos Generales a Seguir¶

Las metodologías se pueden resumir en 6 pasos clave:
Recolectar los datos: Los datos se pueden obtener de diversas fuentes, como sitios web, APIs o bases de datos.
Preprocesar los datos: Requiere realizar tareas como limpieza, transformación y normalización de datos, esenciales para asegurar su calidad antes de su uso.
Explorar los datos: Consiste en un análisis preliminar para identificar patrones, valores faltantes o errores que puedan influir en la etapa de modelado.
Entrenar el modelo: En esta etapa, se construyen y ajustan los modelos utilizando los datos preprocesados, extrayendo información útil para futuras predicciones.
Evaluar el modelo: Se verifica la precisión y el rendimiento del modelo. Si los resultados no son satisfactorios, se regresa a la etapa de entrenamiento para ajustar los parámetros.
Utilizar el modelo: Una vez validado, el modelo se implementa en un entorno real. Su desempeño se monitorea continuamente, lo que puede requerir revisar y mejorar las etapas anteriores.
Los pasos 1, 2 y 3 ya se han detallado en este curso, mientras que las etapas de modelado (entrenamiento, evaluación y predicción) introducen nuevos conceptos que exploraremos a continuación.