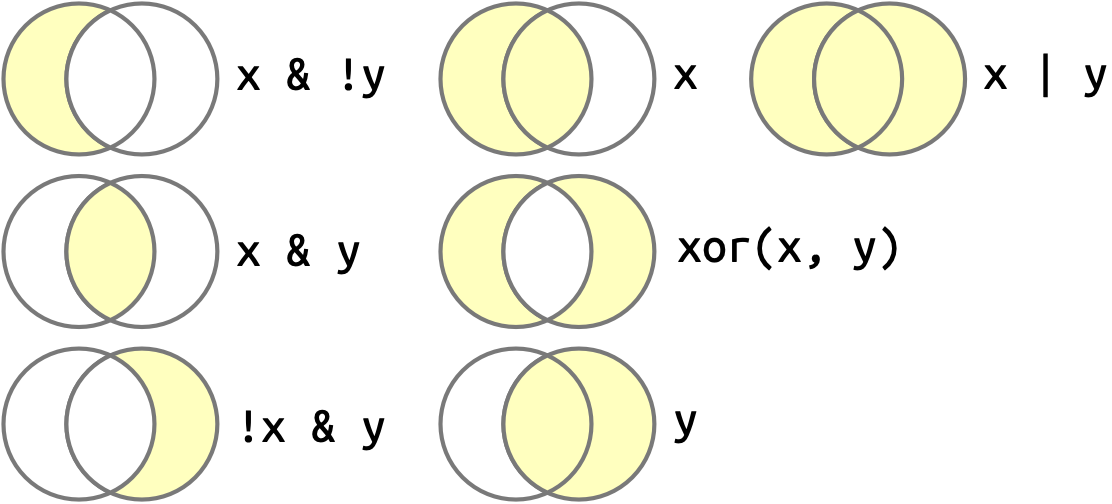
x is the left-hand circle, y is the right-hand circle, and the shaded regions show which parts each operator selects.
In this chapter, you’ll learn tools for working with logical vectors. Logical vectors are the simplest type of vector because each element can only be one of three possible values: TRUE, FALSE, and NA. It’s relatively rare to find logical vectors in your raw data, but you’ll create and manipulate them in the course of almost every analysis.
We’ll begin by discussing the most common way of creating logical vectors: with numeric comparisons. Then you’ll learn about how you can use Boolean algebra to combine different logical vectors, as well as some useful summaries. We’ll finish off with if_else() and case_when(), two useful functions for making conditional changes powered by logical vectors.
Most of the functions you’ll learn about in this chapter are provided by base R, so we don’t need the tidyverse, but we’ll still load it so we can use mutate(), filter(), and friends to work with data frames. We’ll also continue to draw examples from the nycflights13::flights dataset.
However, as we start to cover more tools, there won’t always be a perfect real example. So we’ll start making up some dummy data with c():
This makes it easier to explain individual functions at the cost of making it harder to see how it might apply to your data problems. Just remember that any manipulation we do to a free-floating vector, you can do to a variable inside a data frame with mutate() and friends.
A very common way to create a logical vector is via a numeric comparison with <, <=, >, >=, !=, and ==. So far, we’ve mostly created logical variables transiently within filter() — they are computed, used, and then thrown away. For example, the following filter finds all daytime departures that arrive roughly on time:
It’s useful to know that this is a shortcut and you can explicitly create the underlying logical variables with mutate():
This is particularly useful for more complicated logic because naming the intermediate steps makes it easier to both read your code and check that each step has been computed correctly.
All up, the initial filter is equivalent to:
Beware of using == with numbers. For example, it looks like this vector contains the numbers 1 and 2:
But if you test them for equality, you get FALSE:
What’s going on? Computers store numbers with a fixed number of decimal places so there’s no way to exactly represent 1/49 or sqrt(2) and subsequent computations will be very slightly off. We can see the exact values by calling print() with the digits1 argument:
You can see why R defaults to rounding these numbers; they really are very close to what you expect.
Now that you’ve seen why == is failing, what can you do about it? One option is to use dplyr::near() which ignores small differences:
Missing values represent the unknown so they are “contagious”: almost any operation involving an unknown value will also be unknown:
The most confusing result is this one:
It’s easiest to understand why this is true if we artificially supply a little more context:
So if you want to find all flights where dep_time is missing, the following code doesn’t work because dep_time == NA will yield NA for every single row, and filter() automatically drops missing values:
Instead we’ll need a new tool: is.na().
is.na()
is.na(x) works with any type of vector and returns TRUE for missing values and FALSE for everything else:
We can use is.na() to find all the rows with a missing dep_time:
is.na() can also be useful in arrange(). arrange() usually puts all the missing values at the end but you can override this default by first sorting by is.na():
We’ll come back to cover missing values in more depth in Chapter 18.
dplyr::near() work? Type near to see the source code. Is sqrt(2)^2 near 2?mutate(), is.na(), and count() together to describe how the missing values in dep_time, sched_dep_time and dep_delay are connected.Once you have multiple logical vectors, you can combine them together using Boolean algebra. In R, & is “and”, | is “or”, ! is “not”, and xor() is exclusive or2. For example, df |> filter(!is.na(x)) finds all rows where x is not missing and df |> filter(x < -10 | x > 0) finds all rows where x is smaller than -10 or bigger than 0. Figure 12.1 shows the complete set of Boolean operations and how they work.
x is the left-hand circle, y is the right-hand circle, and the shaded regions show which parts each operator selects.
As well as & and |, R also has && and ||. Don’t use them in dplyr functions! These are called short-circuiting operators and only ever return a single TRUE or FALSE. They’re important for programming, not data science.
The rules for missing values in Boolean algebra are a little tricky to explain because they seem inconsistent at first glance:
To understand what’s going on, think about NA | TRUE (NA or TRUE). A missing value in a logical vector means that the value could either be TRUE or FALSE. TRUE | TRUE and FALSE | TRUE are both TRUE because at least one of them is TRUE. NA | TRUE must also be TRUE because NA can either be TRUE or FALSE. However, NA | FALSE is NA because we don’t know if NA is TRUE or FALSE. Similar reasoning applies with NA & FALSE.
Note that the order of operations doesn’t work like English. Take the following code that finds all flights that departed in November or December:
You might be tempted to write it like you’d say in English: “Find all flights that departed in November or December.”:
This code doesn’t error but it also doesn’t seem to have worked. What’s going on? Here, R first evaluates month == 11 creating a logical vector, which we call nov. It computes nov | 12. When you use a number with a logical operator it converts everything apart from 0 to TRUE, so this is equivalent to nov | TRUE which will always be TRUE, so every row will be selected:
%in%
An easy way to avoid the problem of getting your ==s and |s in the right order is to use %in%. x %in% y returns a logical vector the same length as x that is TRUE whenever a value in x is anywhere in y .
So to find all flights in November and December we could write:
Note that %in% obeys different rules for NA to ==, as NA %in% NA is TRUE.
This can make for a useful shortcut:
arr_delay is missing but dep_delay is not. Find all flights where neither arr_time nor sched_arr_time are missing, but arr_delay is.dep_time? What other variables are missing in these rows? What might these rows represent?dep_time implies that a flight is cancelled, look at the number of cancelled flights per day. Is there a pattern? Is there a connection between the proportion of cancelled flights and the average delay of non-cancelled flights?The following sections describe some useful techniques for summarizing logical vectors. As well as functions that only work specifically with logical vectors, you can also use functions that work with numeric vectors.
There are two main logical summaries: any() and all(). any(x) is the equivalent of |; it’ll return TRUE if there are any TRUE’s in x. all(x) is equivalent of &; it’ll return TRUE only if all values of x are TRUE’s. Like all summary functions, they’ll return NA if there are any missing values present, and as usual you can make the missing values go away with na.rm = TRUE.
For example, we could use all() and any() to find out if every flight was delayed on departure by at most an hour or if any flights were delayed on arrival by five hours or more. And using group_by() allows us to do that by day:
In most cases, however, any() and all() are a little too crude, and it would be nice to be able to get a little more detail about how many values are TRUE or FALSE. That leads us to the numeric summaries.
When you use a logical vector in a numeric context, TRUE becomes 1 and FALSE becomes 0. This makes sum() and mean() very useful with logical vectors because sum(x) gives the number of TRUEs and mean(x) gives the proportion of TRUEs (because mean() is just sum() divided by length()).
That, for example, allows us to see the proportion of flights that were delayed on departure by at most an hour and the number of flights that were delayed on arrival by five hours or more:
There’s one final use for logical vectors in summaries: you can use a logical vector to filter a single variable to a subset of interest. This makes use of the base [ (pronounced subset) operator, which you’ll learn more about in Section 27.2.
Imagine we wanted to look at the average delay just for flights that were actually delayed. One way to do so would be to first filter the flights and then calculate the average delay:
This works, but what if we wanted to also compute the average delay for flights that arrived early? We’d need to perform a separate filter step, and then figure out how to combine the two data frames together3. Instead you could use [ to perform an inline filtering: arr_delay[arr_delay > 0] will yield only the positive arrival delays.
This leads to:
Also note the difference in the group size: in the first chunk n() gives the number of delayed flights per day; in the second, n() gives the total number of flights.
sum(is.na(x)) tell you? How about mean(is.na(x))?prod() return when applied to a logical vector? What logical summary function is it equivalent to? What does min() return when applied to a logical vector? What logical summary function is it equivalent to? Read the documentation and perform a few experiments.One of the most powerful features of logical vectors are their use for conditional transformations, i.e. doing one thing for condition x, and something different for condition y. There are two important tools for this: if_else() and case_when().
if_else()
If you want to use one value when a condition is TRUE and another value when it’s FALSE, you can use dplyr::if_else()4. You’ll always use the first three argument of if_else(). The first argument, condition, is a logical vector, the second, true, gives the output when the condition is true, and the third, false, gives the output if the condition is false.
Let’s begin with a simple example of labeling a numeric vector as either “+ve” (positive) or “-ve” (negative):
There’s an optional fourth argument, missing which will be used if the input is NA:
You can also use vectors for the the true and false arguments. For example, this allows us to create a minimal implementation of abs():
So far all the arguments have used the same vectors, but you can of course mix and match. For example, you could implement a simple version of coalesce() like this:
You might have noticed a small infelicity in our labeling example above: zero is neither positive nor negative. We could resolve this by adding an additional if_else():
This is already a little hard to read, and you can imagine it would only get harder if you have more conditions. Instead, you can switch to dplyr::case_when().
case_when()
dplyr’s case_when() is inspired by SQL’s CASE statement and provides a flexible way of performing different computations for different conditions. It has a special syntax that unfortunately looks like nothing else you’ll use in the tidyverse. It takes pairs that look like condition ~ output. condition must be a logical vector; when it’s TRUE, output will be used.
This means we could recreate our previous nested if_else() as follows:
This is more code, but it’s also more explicit.
To explain how case_when() works, let’s explore some simpler cases. If none of the cases match, the output gets an NA:
Use .default if you want to create a “default”/catch all value:
And note that if multiple conditions match, only the first will be used:
Just like with if_else() you can use variables on both sides of the ~ and you can mix and match variables as needed for your problem. For example, we could use case_when() to provide some human readable labels for the arrival delay:
Be wary when writing this sort of complex case_when() statement; my first two attempts used a mix of < and > and I kept accidentally creating overlapping conditions.
Note that both if_else() and case_when() require compatible types in the output. If they’re not compatible, you’ll see errors like this:
Overall, relatively few types are compatible, because automatically converting one type of vector to another is a common source of errors. Here are the most important cases that are compatible:
NA, which is technically a logical vector, is compatible with everything because every vector has some way of representing a missing value.We don’t expect you to memorize these rules, but they should become second nature over time because they are applied consistently throughout the tidyverse.
A number is even if it’s divisible by two, which in R you can find out with x %% 2 == 0. Use this fact and if_else() to determine whether each number between 0 and 20 is even or odd.
Given a vector of days like x <- c("Monday", "Saturday", "Wednesday"), use an if_else() statement to label them as weekends or weekdays.
Use if_else() to compute the absolute value of a numeric vector called x.
Write a case_when() statement that uses the month and day columns from flights to label a selection of important US holidays (e.g., New Years Day, 4th of July, Thanksgiving, and Christmas). First create a logical column that is either TRUE or FALSE, and then create a character column that either gives the name of the holiday or is NA.
The definition of a logical vector is simple because each value must be either TRUE, FALSE, or NA. But logical vectors provide a huge amount of power. In this chapter, you learned how to create logical vectors with >, <, <=, >=, ==, !=, and is.na(), how to combine them with !, &, and |, and how to summarize them with any(), all(), sum(), and mean(). You also learned the powerful if_else() and case_when() functions that allow you to return values depending on the value of a logical vector.
We’ll see logical vectors again and again in the following chapters. For example in Chapter 14 you’ll learn about str_detect(x, pattern) which returns a logical vector that’s TRUE for the elements of x that match the pattern, and in Chapter 17 you’ll create logical vectors from the comparison of dates and times. But for now, we’re going to move onto the next most important type of vector: numeric vectors.
R normally calls print for you (i.e. x is a shortcut for print(x)), but calling it explicitly is useful if you want to provide other arguments.↩︎
That is, xor(x, y) is true if x is true, or y is true, but not both. This is how we usually use “or” In English. “Both” is not usually an acceptable answer to the question “would you like ice cream or cake?”.↩︎
We’ll cover this in Chapter 19.↩︎
dplyr’s if_else() is very similar to base R’s ifelse(). There are two main advantages of if_else()over ifelse(): you can choose what should happen to missing values, and if_else() is much more likely to give you a meaningful error if your variables have incompatible types.↩︎