Introducción
![]()
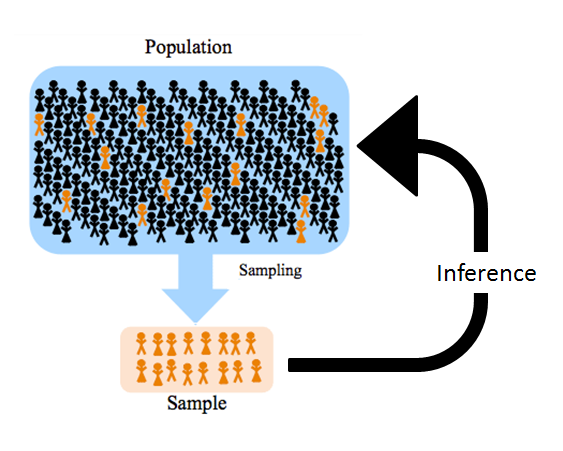
La inferencia estadística es el conjunto de métodos que nos permite extraer conclusiones sobre una población a partir de una muestra. En lugar de observar todos los datos posibles, tomamos una muestra, calculamos estadísticos, y usamos esa información para estimar parámetros, probar hipótesis y cuantificar la incertidumbre de nuestras conclusiones.
Esta sección parte desde los fundamentos del muestreo y las distribuciones de probabilidad, avanza por las herramientas clásicas de inferencia — pruebas de hipótesis e intervalos de confianza — y culmina en el análisis de regresión lineal, donde todos estos conceptos se integran para modelar relaciones entre variables y evaluar su significancia estadística. El hilo conductor es siempre el mismo: aprender a distinguir lo que los datos realmente dicen de lo que podría ser producto del azar.
![]()
A lo largo de la sección se usa
statsmodelscomo librería principal, complementada conscipy.statspara las distribuciones y pruebas básicas.
Conceptos clave
| Concepto | Descripción |
|---|---|
| Población y muestra | La población es el conjunto completo de elementos que queremos estudiar; la muestra es el subconjunto que efectivamente observamos. Toda la inferencia consiste en razonar desde la muestra hacia la población. |
| Variable aleatoria y distribución | Una variable aleatoria asigna un valor numérico a cada resultado posible de un experimento. Su distribución describe qué valores puede tomar y con qué probabilidad. Las distribuciones Normal, t-Student, Chi-cuadrado y F son las más relevantes para esta sección. |
| Media y varianza | La media resume el valor central de una distribución; la varianza mide cuánto se dispersan los valores alrededor de ese centro. Entender cómo se relacionan en una muestra y en la población es fundamental para construir cualquier estimación. |
| Estimador y sesgo | Un estimador es una fórmula que aplicamos a los datos para aproximar un parámetro desconocido. Decimos que es insesgado si en promedio acierta el valor verdadero. La media muestral, por ejemplo, es un estimador insesgado de la media poblacional. |
| Nivel de significancia y valor-p | El nivel de significancia (\(\alpha\)) es el umbral de tolerancia al error que fijamos antes de ver los datos, típicamente 0.05. El valor-p mide la compatibilidad de los datos observados con la hipótesis nula; si es menor que \(\alpha\), rechazamos esa hipótesis. |
| Regresión lineal | Modelo que describe la relación entre una variable dependiente y una o más variables independientes mediante una ecuación lineal. Los coeficientes del modelo cuantifican el efecto de cada predictor, y la inferencia nos dice si esos efectos son estadísticamente distinguibles del ruido. |